Overview
We will go through all the logical steps (and the code!) to write a binary serializer that supports versioning and memory mappability. It is not an automatic process, and it will not contain any data definition schema.
As use cases, we have:
- Creation and reading of game resources/assets
- Game world states (“savegames”)
- Networking transmission/reception
Not having the schema is a problem, and we will try to go around it in the best way possible.
Following is a simple list of terms used in the article, explained in depth in the following sections but useful to have here:
- Serialization: writing to blob from a data structure, or reading from the blob to fill a data structure
- Blob: contiguous section of memory
- Versioning: data with version to skip parts of the serialization
- Memory mappability: ability to load a blob and use it without any processing
Code can be found at my github.com/datadrivenrendering repo.
Source and Data.
The Problem
What is serialization ? Using a simple definition from Wikipedia:
In computing, serialization (US spelling) or serialisation (UK spelling) is the process of translating a data structure or object state into a format that can be stored (for example, in a file or memory data buffer) or transmitted (for example, over a computer network) and reconstructed later (possibly in a different computer environment).
We are about to start a journey of data structure conversion.
There are also two requirements for this system, one strong (versioning) and the other soft (not always possible, the memory mappability).
When converting two different binaries without a schema, we still need to have some sort of structure.
We will rely on the binary itself to reconstruct itself.
Blob
The first concept to get acquainted with is the blob, and a great article is from our friends at the then BitSquid, now working on OurMachinery.
A blob is a contiguous section of memory, that is movable, copiable and self-contained.
We can pass the blob around, and used to build at runtime data structures that we need, even with some complexity.
We will see how later on.
Versioning
Versioning is the strong requirement for this system: we always want to support different versions of binaries.
This makes the other requirement, memory mappability, somewhat not always achievable.
We will see also that later on.
The main inspiration is from Media Molecule Serialization Article (thanks to Oswald Hurlem for this article!), that explains very well how to create a binary versioning serialization system.
The gist of it is to create a global version and use that to skip or not some parts of the binary generated.
It seems too good and easy to be true, and actually the devil’s in the details, and we will see it!
Memory Mappability
The soft requirement, something we would like to have but not always possible.
The ‘why’ we want this feature is because at runtime, we would like to have data in its final form so we just need to use it, without doing more adjustements.
The combination of blob and relative data structures can give you a ready to go binary, that can contain pointers, arrays and strings (and more!).
It is not all easy, as when binary versions differ we will need still to manually serialize the structures. But more on that later!
The idea of memory mappability for me comes from the incredible implementation done by Sony Santa Monica for God of War - I was exposed to the genius ideas of the original creator of the SMScheme, and was honestly blown away. This should be the gold standard for serialization in my opinion, but I digress!
The secret weapon here are some data structures called relative data structures, which I found here in a little more detail and found them very promising, used also in SmSchema as far as I understand, even though in much better way.
The idea of relative data structures is simple:
Anything that contians a pointer, translates the pointer to be an offset from…itself.
In C++ lingo, the address of the data pointed is (this) + offset.
It is genius that you need only to store the offset, as the this is stored for you by the language!
When the offset is 0, the pointer is considered null.
Three data structures have been implemented in this way:
- Relative Pointer
- Relative Array
- Relative String
They work perfectly with the blob of memory we will use as main tool to achieve this.
What is really interesting is that even a normal array can be turned into a Relative Array, and it becomes a really powerful tool.
We will see how in the code.
Serializing, Allocating, Reading, Writing
We need to clear some terms to finally start to see the solution/implementation.
They are all interwined, and honestly they are what required me to rewrite this serialization code few times before understanding better what I am talking about. I still feel I am not precise enough with words, so any feedback is more than appreciated!
Reading and Writing change the process of Serializing and Allocating in different ways, so we better be precise.
Reading:
- Serializing is from Blob to Runtime Data.
- Allocating is for the Runtime part for dynamic structures, or reading from the Blob for Relative Data Structures.
Writing:
- Serializing is from Runtime Data to Blob.
- Allocating is reserving memory into the Blob.
The Solution
We can finally start seeing how we implemented this serialization system.
The process will be particular, a mix depth first and breath first for both allocation and serialization.
Starting from the root data structure, we will visit each member, serialize it and if needed allocate memory from it.
Allocating memory can be both in-blob memory or runtime memory, depending on the situation.
When writing, it will be the in-blob memory. When reading, it could be just moving into the blob memory (for relative structures) or allocating runtime data (for dynamic arrays and such).
One of the strengths of this approach is that if we use all relative data structures we can allocate once and just memory map everything.
For this reason when we write the binary data, we need to leave traces to read the proper memory from the blob, when reading.
Remember, we don’t have any schema so we need to rely on the serialization process to guide us through the bytes.
Serialization: Write
We will start with writing the blob.
I’ve attempted at some diagrams to show a more step-by-step mechanism, so the algorithm can be a little clearer.
In figure 1 we see the runtime data we want to write into our blob.
The data structure contains an array, to show how the algorithm behaves with dynamically allocated memory.
We always have a serialization offset and an allocation offset.
We always allocate from the current end of the blob.
The serialization offset is used to write data into the blob, and can be used to jump around the blob memory, we will see how.
The first step to write into the blob is to allocate from the blob memory the blob header, that contains a version and a mappable flag. We will use that later to decide how we read data.
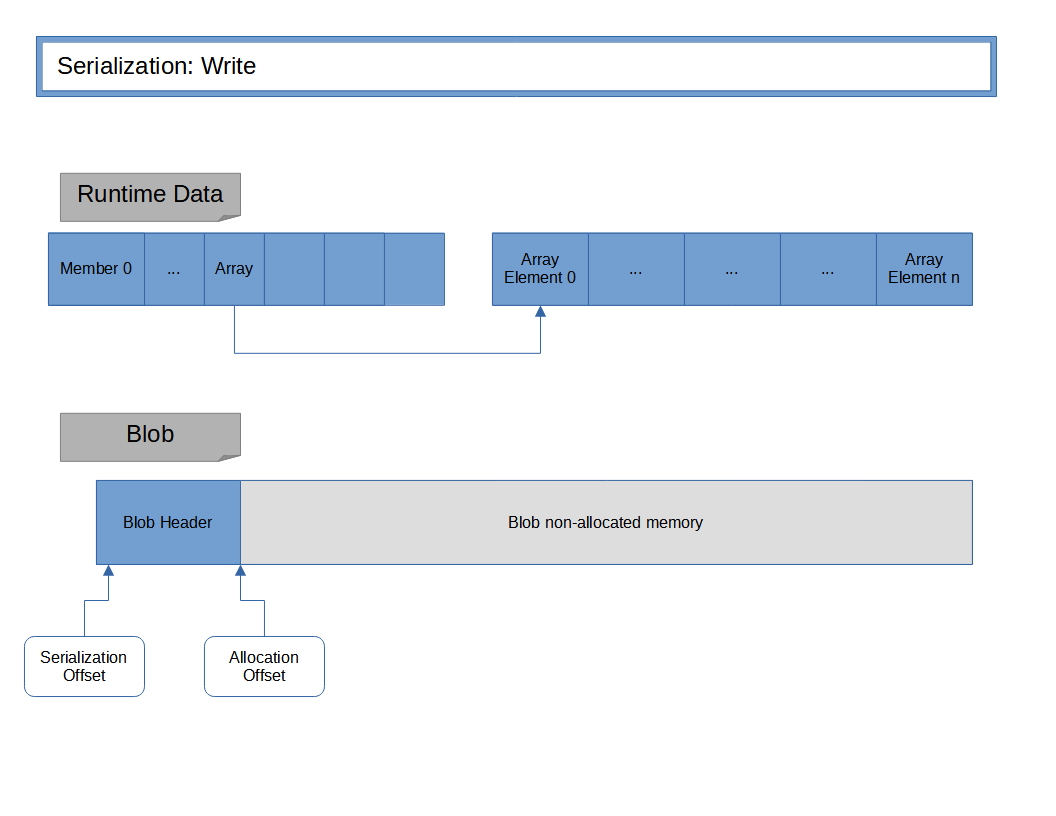
Runtime data and initial blob
Serialization offset is serializing each member of the blob header, like so:
// Write data into blob memory
void MemoryBlob::serialize( u32* data ) {
memcpy( &blob_memory[ serialized_offset ], data, sizeof( u32 ) );
serialized_offset += sizeof( u32 );
}
After each serialization we move the offset by the correct size.
Next we allocate the root data structure into the memory blob, and we start serializing its members, as shown in Figure 2:
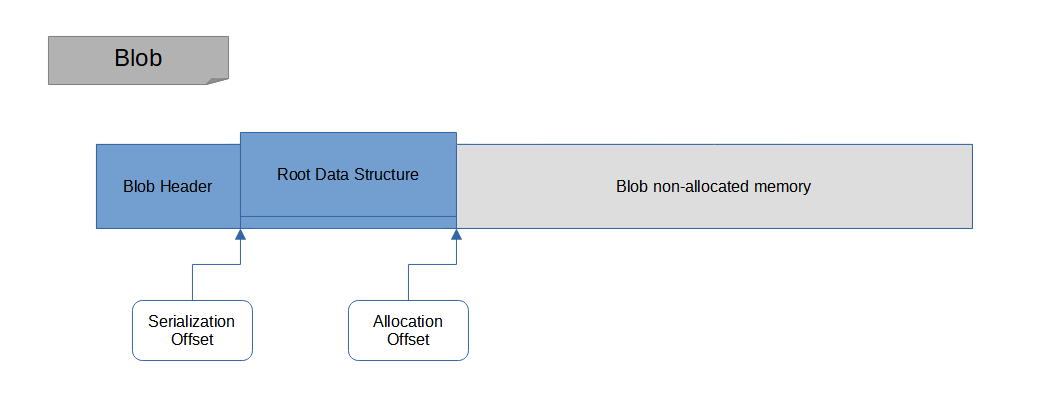
Allocated root data structure, but not serialized
After some primitive member types, we arrive at an array.
In Figure 3, we started serializing the array itself (its struct memory is part of the root data structure), but we miss the array data:
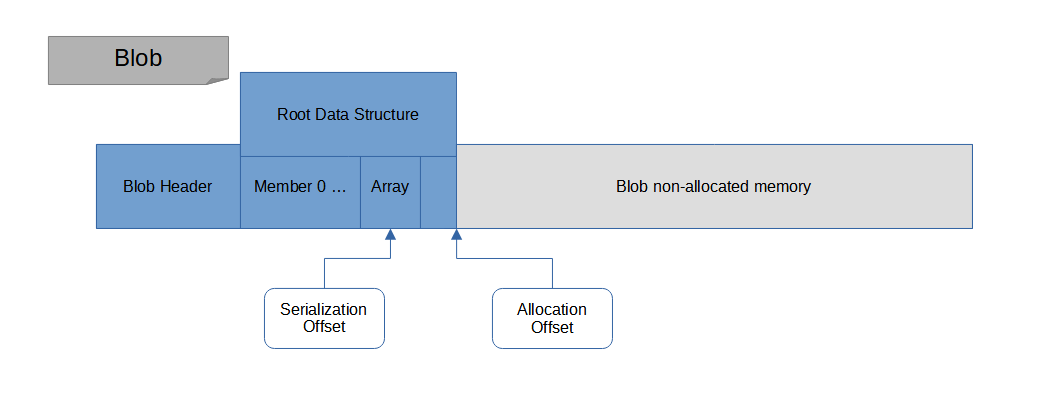
Allocated array data, array struct serialization
We finally allocate the array data and jump serialization to this new location, so we can start serializing each element, as you see from serialization offset:
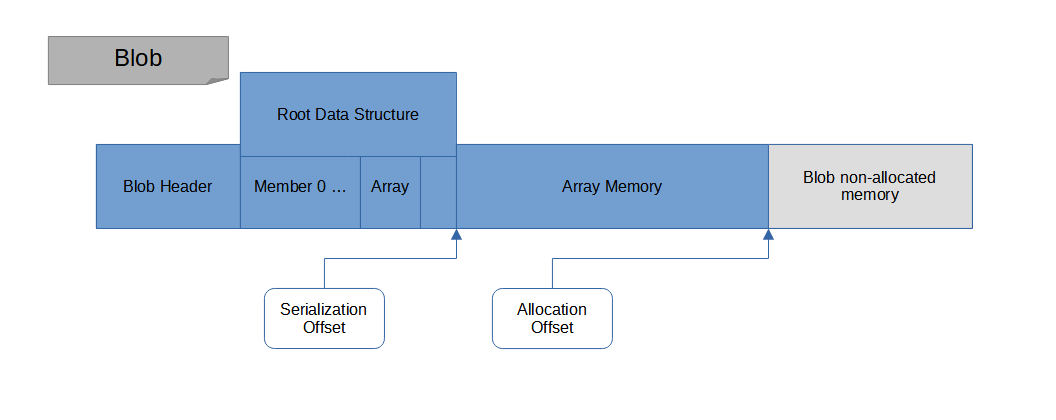
Array data serialization
Once we finished with the array, we store the serialization offset so we can resume the serialization of the other root data structure members:
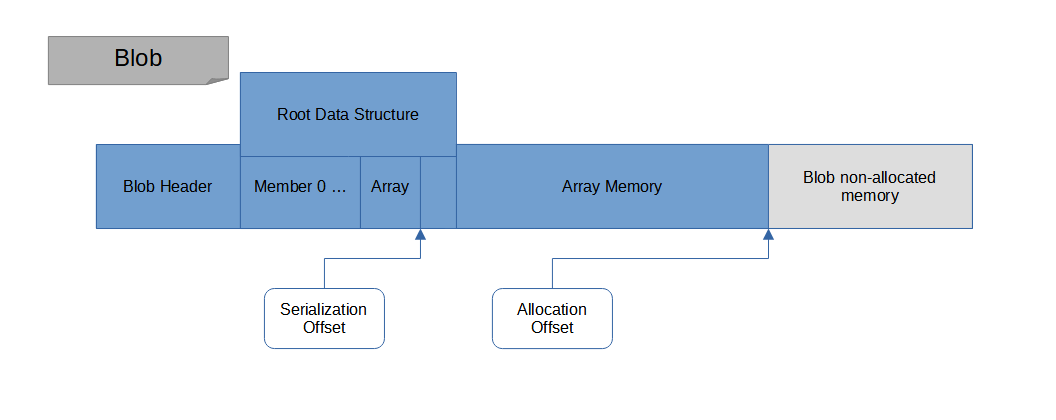
Jump back to serialization of root data structure
In a nutshell this is all the algorithm to serialize an arbitrarly complex network of data structures.
In conjunction with relative data structures, a blob can point to its own memory and enable pointers and arrays to be used without any patch-up.
Serializing Read
Not suprisingly reading is very similar to writing, but the source and destination of the operations are inverted: we read from the blob and write into the runtime data.
There is one huge caveat: mappable blobs.
In that case we don’t need any serialization process, but instead we cast memory to the root data structure and it all works!
In order for that to work, for each data structure that points to other parts of the blob, we need two things:
- Save an offset to read from the blob
- A runtime conversion mechanism between the offset and the needed type.
Let’s see an example of that, the Relative Pointer class.
//
// RelativePointer ////////////////////////////////////////////////////////
//
template <typename T>
struct RelativePointer {
T* get() const;
bool is_equal( const RelativePointer& other ) const;
bool is_null() const;
bool is_not_null() const;
// Operator overloading to give a cleaner interface
T* operator->() const;
T& operator*() const;
void set( char* raw_pointer );
void set_null();
i32 offset;
}; // struct RelativePointer
As we can see we save an offset, but the real power comes from the operator overload.
Let’s see the implementation:
// RelativePointer ////////////////////////////////////////////////////////
template<typename T>
inline T* RelativePointer<T>::get() const {
// For debugging purposes leave the address variable.
char* address = ( ( char* )&this->offset ) + offset;
return offset != 0 ? ( T* )address : nullptr;
}
template<typename T>
inline T* RelativePointer<T>::operator->() const {
return get();
}
template<typename T>
inline T& RelativePointer<T>::operator*() const {
return *( get() );
}
The genius idea, coming from the talk I’ve written before, comes from using the current memory, the offset member variable, to give a reference point in memory, and adding the content of the offset itself to retrieve the memory!
char* address = ( ( char* )&this->offset ) + offset;
Employing this simple trick, you can now point to any part of the blob in a transparent way.
Even for a dynamic array implementation, we can add a similar method and reuse its data to use it as memory mappable array:
// Relative data access.
template<typename T>
inline T* Array<T>::get() {
if ( relative ) {
char* address = ( ( char* )&size ) + capacity;
return capacity != 0 ? ( T* )address : nullptr;
}
return nullptr;
}
Writing Serialization Code
In this section we will go through some examples of data structures to explain the read and write code written.
But first, how do we write our custom serialization code ?
Serializing user data structures
Let’s see a very simple example, a vector2 struct:
// Vec2s //////////////////////////////////////////////////////////////////
struct vec2s {
f32 x;
f32 y;
};
// Serialization
template<>
void MemoryBlob::serialize<vec2s>( vec2s* data ) {
serialize( &data->x );
serialize( &data->y );
}
In the MemoryBlob struct, we have a method that we will use with template specialization to actually specialize the serialization code path.
Remember, there is no schema so we use the data structure itself to guide the serialization.
The method that we use with template specialization is this:
template<typename T>
inline void MemoryBlob::serialize( T* data ) {
// Should not arrive here!
hy_assert( false );
}
Thus we need to implement our own version.
Template Specialization Caveat
The correct way to use template specialization without template errors, is to define in an header the following method:
template<>
void hydra::MemoryBlob::serialize<vec2s>( vec2s* data );
And then in a cpp the specialized version.
Versioning
Let’s see the serialization code of a data structure with versioning:
//
//
struct EntityBlueprint {
RelativeString name;
u32 v1_padding; // Added to test different versions.
RelativePointer<RenderingBlueprint> rendering;
RelativePointer<AnimationBlueprint> animation;
vec2s position;
f32 offset_z;
}; // struct EntityBlueprint
template<>
void hydra::MemoryBlob::serialize<EntityBlueprint>( EntityBlueprint* data ) {
serialize( &data->name );
if ( serializer_version > 0 )
serialize( &data->v1_padding );
serialize( &data->rendering );
serialize( &data->animation );
if ( serializer_version > 1 ) {
serialize( &data->position );
} else {
// When reading, we should still initialize variables to a 'valid' state.
data->position = { 0.f, 0.f };
}
serialize( &data->offset_z );
}
This is a test data structure I was using to try the serialization system itself.
It serializes an Entity into a Scene.
I’ve added some padding as test, but then the position as real need for a second version.
Like the Little Big Planet serialization system, the data structure will contain all the members of all its history.
It is the serializer code itself that will jump the members not needed.
Serializing relative pointers
Let’s see the writing code of the Relative Pointers:
template<typename T>
void MemoryBlob::serialize( RelativePointer<T>* data ) {
//...
{
// WRITING!
// Data --> Blob
// Calculate offset used by RelativePointer.
// Remember this:
// char* address = ( ( char* )&this->offset ) + offset;
// Serialized offset points to what will be the "this->offset"
// Allocated offset points to the still not allocated memory,
// Where we will allocate from.
i32 data_offset = allocated_offset - serialized_offset;
serialize( &data_offset );
// To jump anywhere and correctly restore the serialization process,
// cache the current serialization offset
u32 cached_serialized = serialized_offset;
// Move serialization to the newly allocated memory at the end of the blob.
// Serialization is where we WRITE code!
serialized_offset = allocated_offset;
// Allocate memory in the blob
allocate_static<T>();
// Serialize/visit the pointed data structure
serialize( data->get() );
// Restore serialized
serialized_offset = cached_serialized;
}
}
Code is heavily commented to help understanding what is happening.
The reading code is as follows:
// READING!
// Blob --> Data
i32 source_data_offset;
serialize( &source_data_offset );
// Early out to not follow null pointers.
if ( source_data_offset == 0 ) {
data->offset = 0;
return;
}
// This is the important bit.
// Use the offset to the passed member variable to calculate the DESTINATION offset
// to write to.
data->offset = get_relative_data_offset( data );
// Allocate memory and set pointer
allocate_static<T>();
// Cache source serialized offset.
u32 cached_serialized = serialized_offset;
// Move serialization offset.
// The offset is still "this->offset", and the serialized offset
// points just right AFTER it, thus move back by sizeof(offset).
// Serialization is where READ from in the blob!
serialized_offset = cached_serialized + source_data_offset - sizeof(u32);
// Serialize/visit the pointed data structure, using the offset calculated above.
serialize( data->get() );
// Restore serialization offset
serialized_offset = cached_serialized;
There is a method here that is very important: get_relative_data_offset.
This highlights how we can use the struct itself to guide the serialization:
i32 MemoryBlob::get_relative_data_offset( void* data ) {
// data_memory points to the newly allocated data structure to be used at runtime.
const i32 data_offset_from_start = ( i32 )( ( char* )data - data_memory );
const i32 data_offset = allocated_offset - data_offset_from_start;
return data_offset;
}
When we read, we are writing into some data structure, that can differ from the binarized data.
Let’s say the binary has some missing fields (an older version), we need to calculate the writing offset based on our code.
So first we get the offset of the passed variable from the start of the memory, then we calculate the offset to the data memory that will be allocated shortly after.
With this code, we actually showed the algorithm that, with little modifications, can be adapted to any data structure.
NOTE: something that really confused me at the beginning was the usage of data, serialization offset and allocation offset.
The fact is that they change meaning when we are reading and when we are writing, so we need to mentally picture it to really understand how they are used.
I tried to add comments to help remembering this.
Serializing relative arrays and dynamic arrays
Relative Arrays are very similar to Relative Pointers, but they just store more data and contain a size member.
...
allocate_static( data->size * sizeof( T ) );
for ( u32 i = 0; i < data->size; ++i ) {
T* data = &data->get()[ i ];
serialize( data );
}
The only real difference is that we iterate through all the members by calling their serialize method.
Special: writing blob from a json file
Something we might need to do, especially in a build step, is to convert from a non-binary format to our blob.
This is something done a lot in games, so that the final binary format is as fast to use as possible, compared to always parsing a json (or other formats) and doing some work on the loaded data.
I’ve added an example of writing a json file containing commands for a cutscene system, and they use a different way of writing the blob.
So far we’ve only seen the passing of an already binary version of data, to be compacted in a blob.
In this case we are performing a real conversion.
Let’s start with the json (available under data\articles\SerializationDemo\cutscene.json) describing the cutscene:
{
"name":"new_game",
"scene": "",
"commands" : [
{
"type" : "fade",
"start" : 0.0,
"end" : 1.0,
"duration" : 0.0
},
{
"type" : "move_entity",
"x" : -16,
"y" : -8,
"instant" : true,
"entity_name" : "cronos_mum"
},
{
"type" : "dialogue",
"text" : "{SPEED=0.025}Crono...{PAGE}Crono!{PAGE}Crono, are you still sleeping?{PAGE} "
}
]
}
We have different commands that needs to be parsed and converted in a binary format.
As you probably spotted, I was using this serialization system with Chrono Trigger in mind as something to clone, and even if I did not cloned the whole game, I could test a cutscene and some gameplay informations to be used.
Anyway, let’s see the conversion code.
First, the main data structures:
//
//
struct CutsceneEntry {
CutsceneCommandType type;
RelativeArray<u8> data;
}; // struct CutsceneEntry
//
//
struct CutsceneBlueprint {
RelativeArray<CutsceneEntry> entries;
static constexpr u32 k_version = 0;
}; // struct CutsceneBlueprint
I should change the names maybe, but the root data structure is the CutsceneBlueprint. It contians just an array of entries, each one with some data associated and a type.
First, we create the blob and allocate a fixed size (yes, it should be dynamic, I know!):
MemoryBlob blob;
blob.write<CutsceneBlueprint>( allocator, 0, blob_size, nullptr );
Passing a ‘nullptr’ as last argument means we don’t have any root data structure ready to be serialized.
We instead proceed manually to build the blob.
In this case we heavily use allocate and allocate and set methods.
// Reserve memory for root data structure
CutsceneBlueprint* root = blob.allocate_static<CutsceneBlueprint>();
// Allocate array data and set its offset:
blob.allocate_and_set( root->entries, num_entries );
With this code we can already write into the single entries, like this:
// Declare an empty std::string to convert json strings
std::string name_string;
// Read the json entries
json entries = parsed_json[ "commands" ];
for ( u32 i = 0; i < entries.size; ++i ) {
json element = entries[ i ];
// Convert field 'type' to std::string
element[ "type" ].get_to( name_string );
// Access the allocated array to write into its entries.
CutsceneEntry& entry = root->entries[ i ];
// Yes yes, this can be improved!
if ( name_string.compare( "dialogue" ) == 0 ) {
element[ "text" ].get_to( name_string );
// Allocate memory for the string + null terminator!
char* memory = blob.allocate_static( name_string.size() + 1 );
memcpy( memory, name_string.c_str(), name_string.size() );
memory[ name_string.size() ] = 0;
entry.type = CutsceneCommandType::Dialogue;
// Calculate the offset for the data RelativeArray of the CutsceneEntry
entry.data.set( memory, ( u32 )name_string.size() );
}
...
}
With this simple code we can see a common pattern when writing into the blob from a non binary input.
We allocate the root data structure, and we use it to fill the blob.
Every time we need to allocate memory, we do it and then use the newly allocated memory.
I will leave more examples in the source code, also with pointers and arrays of arrays, but the mindset is this one!
For reading this, if we did everything correctly and the data version is the latest, we can simply memory map it and use it.
Conclusion
We saw in depth a serialization system that supports memory mappability.
We explored the different basic bricks that makes this possible, and presented a couple of examples (and included more in the code) to see different usages.
While not perfect, I believe this could be a great starting point to serializing anything needed into your code.
Adding a custom serialized type is a matter of adding a method, both for reading and writing.
I decided to use templates instead of the Little Big Planet C-style way just to have something more modern, but a C version could be used that is very similar.
Binary compatibility is not 100% safe, I am sure there are edge cases that breaks (like padding between member variables!), but I feel that this is a good start.
There are still some things that needs to be solved, like the support for dynamically sized blobs (as reallocating during the serialization invalidates the memory you are using, needing a more careful approach), and the API it’s still not very mature - code ergonomy is not high.
Personally I already converted hydra fx to use this system and it works like a charm, and I am planning to use it more and more to refine the system better.
Code can be found at my github.com/datadrivenrendering repo.
Source and Data.
As always, please send any feedback to my twitter.
Hope you enjoyed!