UI using ImGUI, SDL and the code generated with this article.
Motivation
Following my previous article about Flatbuffers and data reflection the quest for Data-Driven Rendering continues! In this article I want to show how to write a very simple code-generator to help you automate writing of code in any language. The code is here:
https://github.com/JorenJoestar/DataDrivenRendering
There is a balance that constantly needs to be found between code and data, and having a code-generator in my opinion helps tremendously in focus on the code that is necessary to be written. From a data perspective, normally the ‘baking’ pipeline is a series of DCC formats as source transformed into very project specific and optimized data. Code-wise, depending on the engine/technology you are using, ‘baking’ of the code is more uncommon. In a time in which iteration time has become almost more important than the tech itself, playing with this balance can be the key for any successful software. It could sound exaggerated, but I really believe in that. As always, both ImGui and SDL will be our sword and shields for this adventure. This will be the second step into data-driven rendering: code generation.
Are we writing a compiler ?
Short answer: yes!
Long answer: we will be writing the simplest possible compiler that reads a source file and transform in a destination file, like Flatbuffers.
There are few links on both theory and practice that can help shed some light on the subject: The “Dragon Book” (called because of the dragon in the cover) is still THE to-go in compiler writing as far as I know. It is an intense book and explores writing a full compiler with depth, starting from Automata theory (just reminds me of how everything you study can be useful, I did 2 exams at University about that, wondering when I would use it! Hello prof Di Battista!) to full code examples:
https://www.amazon.com/Compilers-Principles-Techniques-Tools-2nd/dp/0321486811
This is for me the best website on the subject, very precise and readable and follows closely what is inside the Dragon Book:
https://craftinginterpreters.com/
And github page:
https://github.com/munificent/craftinginterpreters
My interest was rekindled in 2015, when I was following the amazing Casey Muratori and his Handmade Hero. He generates code for introspection purposes, and really show a simple and effective way of generating code that works for you.
Wikipedia itself also contains a lot of good articles on the subject. The more you know about the it, the more you want to know. It is fascinating and very, very deep!
Compiler 101
A real compiler is a very complex and fascinating subject/software so I will try to get the simplest possible approach giving my (flawed and incomplete) perspective.
A compiler is a series of transformations applied to data (you can apply this definition to every software actually…).
The input data is a text, and normally the output is still text, but with very different meaning.
The raw depth of the subject is astonishing, consider that we are defining a grammar and thus a language, and how to express concepts into it.
The main steps are the following:
- Lexer/scanner/tokenizer
- Parser
- Code generation
We will define the code generator from a custom language called HDF (Hydra Definition Format) to C++. HDF will be a subset of Flatbuffers in this exercise, but once the concepts are clear it can be expanded to more stuff.
Lexer/Scanner/Tokenizer
A lexer or scanner (or tokenizer) is a software that translates an input string into a list of Tokens based on Lexemes. A Lexeme is one or more characters that create a Token. Think of a keyword (like ‘if’, ‘class’, ‘static’ …).
A Token is identified by a unique Lexeme and abstracts the Lexeme itself. It normally contains a type and some attributes, for example it can save where that lexeme is into the input text, the line. The final structure of the token can vary a bit.
In trying to find a simple definition for this step:
The act of Tokenizing is the act of abstracting the input text.
For example, given the following input text:
static void amazing_method() {};
It will generate the list of tokens ‘keyword, identifier, identifier, open parenthesis, close parenthesis, open brace, close brace, semicolon’.
This IS abstracting the text!
Normally a lexer/scanner is used by the parser to go through the code and retrieve a token and use it in some way. Let’s start seeing what a lexer could be!
Code
Let’s see the code used by the lexer.
First thing will be to define the Token:
// Lexer/Tokenizer code. It is abstract enough so is not grammar specific.
//
struct Token {
enum Type {
Token_Unknown,
Token_OpenParen,
Token_CloseParen,
Token_Colon,
Token_Semicolon,
Token_Asterisk,
Token_OpenBracket,
Token_CloseBracket,
Token_OpenBrace,
Token_CloseBrace,
Token_OpenAngleBracket,
Token_CloseAngleBracket,
Token_String,
Token_Identifier,
Token_Number,
Token_EndOfStream,
}; // enum Type
Type type;
StringRef text;
}; // struct Token
It is basically a enum with a StringRef. A StringRef is basically a substring - used to avoid allocations when parsing by simply saving where the Token is in the parsed text and how long it is.
Next is the Lexer itself:
//
// The role of the Lexer is to divide the input string into a list of Tokens.
struct Lexer {
char* position = nullptr;
uint32_t line = 0;
uint32_t column = 0;
bool error = false;
uint32_t error_line = 0;
}; // struct Lexer
The most important variable is position - it saves where the Lexer is in the current text for parsing.
From now on there will be only methods.
First some character classification that will help the Lexer:
//
// All those methods are to classify a character.
//
inline bool IsEndOfLine( char c ) {
bool Result = ((c == '\n') || (c == '\r'));
return(Result);
}
inline bool IsWhitespace( char c ) {
bool Result = ((c == ' ') || (c == '\t') || (c == '\v') || (c == '\f') || IsEndOfLine( c ));
return(Result);
}
inline bool IsAlpha( char c ) {
bool Result = (((c >= 'a') && (c <= 'z')) || ((c >= 'A') && (c <= 'Z')));
return(Result);
}
inline bool IsNumber( char c ) {
bool Result = ((c >= '0') && (c <= '9'));
return(Result);
}
These should be quite straightforward.
Then we have the most important method for the lexer: nextToken. This method will contain all the logic to go to the next token, and we will see it step by step.
First is skipping all the whitespaces (empty characters, tabs, returns, etc) to arrive at the correct character in the text.
//
// This is the main method. Skip whitespaces and get next token. Save also the current position in the input string.
//
void nextToken( Lexer* lexer, Token& token ) {
// Skip all whitespace first so that the token is without them.
skipWhitespace( lexer );
The code for skipping the whitespace is pretty straight-forward. First it checks if it is a pure whitespace:
void skipWhitespace( Lexer* lexer ) {
// Scan text until whitespace is finished.
for ( ;; ) {
// Check if it is a pure whitespace first.
if ( IsWhitespace( lexer->position[0] ) ) {
// Handle change of line
if ( IsEndOfLine( lexer->position[0] ) )
++lexer->line;
// Advance to next character
++lexer->position;
Then it checks if it is a single line comment:
} // Check for single line comments ("//")
else if ( (lexer->position[0] == '/') && (lexer->position[1] == '/') ) {
lexer->position += 2;
while ( lexer->position[0] && !IsEndOfLine( lexer->position[0] ) ) {
++lexer->position;
}
And last it checks for c-style multiline comments:
} // Check for c-style multi-lines comments
else if ( (lexer->position[0] == '/') && (lexer->position[1] == '*') ) {
lexer->position += 2;
// Advance until the string is closed. Remember to check if line is changed.
while ( !((lexer->position[0] == '*') && (lexer->position[1] == '/')) ) {
// Handle change of line
if ( IsEndOfLine( lexer->position[0] ) )
++lexer->line;
// Advance to next character
++lexer->position;
}
if ( lexer->position[0] == '*' ) {
lexer->position += 2;
}
}
else {
break;
}
}
}
After skipped all the whitespaces, we initialize the new token:
// Initialize token
token.type = Token::Token_Unknown;
token.text.text = lexer->position;
token.text.length = 1;
token.line = lexer->line;
We get the current character and advance the position, so we can analize it.
char c = lexer->position[0];
++lexer->position;
Here comes the character analisys using a simple switch.
switch ( c ) {
case '\0':
{
token.type = Token::Token_EndOfStream;
} break;
case '(':
{
token.type = Token::Token_OpenParen;
} break;
case ')':
{
token.type = Token::Token_CloseParen;
} break;
case ':':
{
token.type = Token::Token_Colon;
} break;
case ';':
{
token.type = Token::Token_Semicolon;
} break;
case '*':
{
token.type = Token::Token_Asterisk;
} break;
case '[':
{
token.type = Token::Token_OpenBracket;
} break;
case ']':
{
token.type = Token::Token_CloseBracket;
} break;
case '{':
{
token.type = Token::Token_OpenBrace;
} break;
case '}':
{
token.type = Token::Token_CloseBrace;
} break;
There are some special cases left. First parsing a string starting from a ‘"’ character. It requires to scan the text until it finds another ‘"’ to indicate the end of the string. It also supports multiple-line strings with the characters “\” (double back-slash)
case '"':
{
token.type = Token::Token_String;
token.text.text = lexer->position;
while ( lexer->position[0] &&
lexer->position[0] != '"' )
{
if ( (lexer->position[0] == '\\') &&
lexer->position[1] )
{
++lexer->position;
}
++lexer->position;
}
// Saves total string length
token.text.length = lexer->position - token.text.text;
if ( lexer->position[0] == '"' ) {
++lexer->position;
}
} break;
Then the final classification step: first is checking if the token is an identifier (a string literal that starts with a character and is followed by characters, underscores or numbers). If not a identifier, check to see if it is a number. This should be expanded to correctly parse numbers, but for now is not used.. If everything else fails, than we don’t recognize the token.
default:
{
// Identifier/keywords
if ( IsAlpha( c ) ) {
token.type = Token::Token_Identifier;
while ( IsAlpha( lexer->position[0] ) || IsNumber( lexer->position[0] ) || (lexer->position[0] == '_') ) {
++lexer->position;
}
token.text.length = lexer->position - token.text.text;
} // Numbers
else if ( IsNumber( c ) ) {
token.type = Token::Token_Number;
}
else {
token.type = Token::Token_Unknown;
}
} break;
}
}
With this code we already have a working Lexer! I like to use the lexer in an abstract way - not knowing anything about the underlying language - so that it can be reused for different custom languages (Dr.Wily eyebrows movement goes here).
If you want to dive deeper into this, the amazing Crafting Interpreters contains a great page on scanning:
https://www.craftinginterpreters.com/scanning.html
Also, some c-style parsing can be found here from the amazing Niklas Frykohlm:
https://github.com/niklasfrykholm/nflibs/blob/master/nf_json_parser.c
And another amazing parser from STB:
https://github.com/nothings/stb/blob/master/stb_c_lexer.h
Parser
So far we have abstracted the input text into a list of Tokens, and now we need to generate some more information before arriving at generating new code.
As far as I understood it, a parser reads the tokens and generates an Abstract Syntax Tree.
Sometimes, and in simpler parsers, the act of parsing itself can generates a new code if the language we are targeting is simple. Again, I prefer to separate Lexer and Parser to reuse the Lexer for different languages and separate the responsabilities!
Given a list of tokens and a grammar, a parser generates an Abstract Syntax Tree.
It gives meaning to the input text, and is responsible to check the syntax correctness.
A simple definition for a grammar is the following:
A grammar is a set of production rules that transforms a series of non-terminals into terminals.
Putting everything in the perspective of data and transformations we can define:
- Terminals are finalized data
- Non-terminals are data that must be transformed
- Production rules are transformations of non-terminals to terminals
Another definition of a parser than it could be :
A parser is a software that transforms non-terminals in terminals following production rules.
Grammar
It is time to write the formal grammar (a context-free grammar) and see how it maps to code. It will be very simple — much simpler than many examples you find around — but it is a starting point. We will not deal with any expression, statements and such, not in the context of this code generator. I will point out some examples for more complex stuff, but I want to study more the subject for that to be more precise about the subject.
Each line will be a production rule (a transformation), with the left-side being always a non-terminal. We are using regular expressions syntax here:
- alphabet → [a-zA-z]
- number →[0–9]
- identifier → alphabet (alphabet | number | “_”)*
- variable_declaration → identifier identifier “;”
- struct_declaration → “struct” identifier “{“ (variable_declaration)+ “}” “;”
- enum_declaration → “enum” identifier “{“ (identifier)+ “}”
- module → (struct_declaration | enum_declaration)+*
First we define what an identifier is — a sequence of alpha-numerical characters that can contains also the underscore character.Notice that with the identifier production rule, the identifier cannot start with an underscore. A variable then is declared simply by two identifiers: the first for the type and the second for the name, following a semicolon. A struct is simply a list of variable declarations. Notice the “+” in the rule — this means that at least one element must be present. Enums are literally a name for the enum and a list of identifiers in curly braces. Finally the module is the root of our grammar. It will contain all the declarations we describe. See it as the data file we are writing to generate the code — one file is one module. Now that we defined a simple grammar, we can move to the theory behind the parser.
Predictive Recursive Descent Parser
The grammar we defined is a context-free-grammar. Depending on the type of grammar we can write different parsers. One of the most common type of parser (and easier to start with) is the Predictive Recursive Descent Parser, and that is what we will write given our grammar. You can dive into all the details of writing a context-free grammar, writing a Left-to-right Leftmost-derivation grammar (LL(k)) and such and be amazed by all the concepts behind.
Again, I am personally starting on this subject, so my knowledge is not deep.
Back to the parser, the main characteristics of this parser are:
- Descent = top-down. Start from root and generate the Abstract Syntax Tree.
- Recursive = the parser has mutually recursive methods, one for each non-terminal.
- Predictive = no backtracking needed. For our simple grammar we do not need any backtracking.
So the parser will start from the root (module non-terminal) and by sequentially reading all the tokens will generate a tree that represent our syntax.
Let’s see some code!
Code
The central piece of code is the Parser. It uses the Lexer and saves the Types by parsing the input text.
//
// The Parser parses Tokens using the Lexer and generate an Abstract Syntax Tree.
struct Parser {
Lexer* lexer = nullptr;
ast::Type* types = nullptr;
uint32_t types_count = 0;
uint32_t types_max = 0;
}; // struct Parser
Let’s have a look at the class Type. This class will let us identify correctly primitive types, enums, struct and commands - a special keyword I create to show a concept that can be used away from the canonical C/C++ languages. By saving a list of names and types we can successfully parse all the types listed above.
//
// Define the language specific structures.
namespace ast {
struct Type {
enum Types {
Types_Primitive, Types_Enum, Types_Struct, Types_Command, Types_None
};
enum PrimitiveTypes {
Primitive_Int32, Primitive_Uint32, Primitive_Int16, Primitive_Uint16, Primitive_Int8, Primitive_Uint8, Primitive_Int64, Primitive_Uint64, Primitive_Float, Primitive_Double, Primitive_Bool, Primitive_None
};
Types type;
PrimitiveTypes primitive_type;
StringRef name;
std::vector<StringRef> names;
std::vector<const Type*> types;
bool exportable = true;
}; // struct Type
} // namespace ast
And now the actual code making the magic happens! Entry point for the parsing is generateAST. It simply goes through ALL the tokens until it reaches the end of the file. At this level of parsing, we parse only identifiers (keywords like ‘struct’, ‘enum’, …).
void generateAST( Parser* parser ) {
// Read source text until the end.
// The main body can be a list of declarations.
bool parsing = true;
while ( parsing ) {
Token token;
nextToken( parser->lexer, token );
switch ( token.type ) {
case Token::Token_Identifier:
{
identifier( parser, token );
break;
}
case Token::Type::Token_EndOfStream:
{
parsing = false;
break;
}
}
}
}
The method ‘identifier’ searches for the language keywords and acts accordingly. The method ‘expectKeyword’ simply checks that the keywords are the same.
inline void identifier( Parser* parser, const Token& token ) {
// Scan the name to know which
for ( uint32_t i = 0; i < token.text.length; ++i ) {
char c = *(token.text.text + i);
switch ( c ) {
case 's':
{
if ( expectKeyword( token.text, 6, "struct" ) ) {
declarationStruct( parser );
return;
}
break;
}
case 'e':
{
if ( expectKeyword( token.text, 4, "enum" ) ) {
declarationEnum( parser );
return;
}
break;
}
case 'c':
{
if ( expectKeyword( token.text, 7, "command" ) ) {
declarationCommand( parser );
return;
}
break;
}
}
}
}
The next methods are the real core of parsing a language. When declaring a struct, the token we have are:
- Identifier ‘struct’ (parsed already by generateAST method)
- Name of the struct
- Open braces
- Zero or more variables
The method expectToken checks the presence of the expected token and saves the line if an error occurs.
inline void declarationStruct( Parser* parser ) {
// name
Token token;
if ( !expectToken( parser->lexer, token, Token::Token_Identifier ) ) {
return;
}
// Cache name string
StringRef name = token.text;
if ( !expectToken( parser->lexer, token, Token::Token_OpenBrace ) ) {
return;
}
// Add new type
ast::Type& type = parser->types[parser->types_count++];
type.name = name;
type.type = ast::Type::Types_Struct;
type.exportable = true;
// Parse struct internals
while ( !equalToken( parser->lexer, token, Token::Token_CloseBrace ) ) {
if ( token.type == Token::Token_Identifier ) {
declarationVariable( parser, token.text, type );
}
}
}
The parsing of a variable is even simpler, just a type followed by the name. When reading the type, it searches through the list of all types saved until then.
inline void declarationVariable( Parser* parser, const StringRef& type_name, ast::Type& type ) {
const ast::Type* variable_type = findType( parser, type_name );
Token token;
// Name
if ( !expectToken( parser->lexer, token, Token::Token_Identifier ) ) {
return;
}
// Cache name string
StringRef name = token.text;
if ( !expectToken( parser->lexer, token, Token::Token_Semicolon ) ) {
return;
}
type.types.emplace_back( variable_type );
type.names.emplace_back( name );
}
The parsing of the enum is:
- ‘enum’ keyword
- Enum name
- (optional) Semicolon and type, taken from Flatbuffers syntax
- Open brace
- List of identifiers that corresponds to the enum values
inline void declarationEnum( Parser* parser ) {
Token token;
// Name
if ( !expectToken( parser->lexer, token, Token::Token_Identifier ) ) {
return;
}
// Cache name string
StringRef name = token.text;
// Optional ': type' for the enum
nextToken( parser->lexer, token );
if ( token.type == Token::Token_Colon ) {
// Skip to open brace
nextToken( parser->lexer, token );
// Token now contains type_name
nextToken( parser->lexer, token );
// Token now contains open brace.
}
if ( token.type != Token::Token_OpenBrace ) {
return;
}
// Add new type
ast::Type& type = parser->types[parser->types_count++];
type.name = name;
type.type = ast::Type::Types_Enum;
type.exportable = true;
// Parse struct internals
while ( !equalToken( parser->lexer, token, Token::Token_CloseBrace ) ) {
if ( token.type == Token::Token_Identifier ) {
type.names.emplace_back( token.text );
}
}
}
A command is a special construct that I use in my code, normally with a CommandBuffer, and with the current syntax from HDF:
command WindowEvents {
Click {
int16 x;
int16 y;
int16 button;
}
Move {
int16 x;
int16 y;
}
Wheel {
int16 z;
}
};
And this is the parsing of the command. I think this can be the best example of mapping between the language and the parsing. Parsing is:
- Name
- Open brace
- Scan of identifiers until close brace
- For each identifier, add a type and scan for internal variables.
inline void declarationCommand( Parser* parser ) {
// name
Token token;
if ( !expectToken( parser->lexer, token, Token::Token_Identifier ) ) {
return;
}
// Cache name string
StringRef name = token.text;
if ( !expectToken( parser->lexer, token, Token::Token_OpenBrace ) ) {
return;
}
// Add new type
ast::Type& command_type = parser->types[parser->types_count++];
command_type.name = name;
command_type.type = ast::Type::Types_Command;
command_type.exportable = true;
// Parse struct internals
while ( !equalToken( parser->lexer, token, Token::Token_CloseBrace ) ) {
if ( token.type == Token::Token_Identifier ) {
// Create a new type for each command
// Add new type
ast::Type& type = parser->types[parser->types_count++];
type.name = token.text;
type.type = ast::Type::Types_Struct;
type.exportable = false;
while ( !equalToken( parser->lexer, token, Token::Token_CloseBrace ) ) {
if ( token.type == Token::Token_Identifier ) {
declarationVariable( parser, token.text, type );
}
}
command_type.names.emplace_back( type.name );
command_type.types.emplace_back( &type );
}
}
}
Abstract Syntax Tree
We choose to simply have data definitions, and I’ve decided that the nodes of the tree will be types. A type can be a primitive type, a container of variables (like a Struct in C, but without methods) enums and commands. Commands are just a way of showing the creation of a construct that I use and requires some boilerplate code, but I don’t want to write that code. If we remember the definition of the class Type from the code before, it all boils down to a name,a list of names and optionally types. With this simple definition I can express primitive types, structs and enums all in one! For enums, I save the anme of the enum and in the name list all the different values. That is enough to later generate the code. For structs, again the name is saved, and then the variables. A variable is a tuple of identifiers ‘type, name’. When parsing them, the type is searched in the registered ones. A trick here is to initialize the parser with primitive types, and then add each type (both struct and enums) when parsing them.
Code Generation
The last stage will generate the files in the language that we want, using the informations from the AST. This part will literally write the code for us, the all purpose of this code. The most fundamental question is: “what code do I want to generate?”. A simple but deep question. We are trying to remove the writing of boilerplate code from or lives, so anything that you consider boilerplate and easy to automate goes here. Even if until here we wrote in C++, the final output can be any language. This means that you can define data and translate it to multiple languages!
For our example, we will output C++ code and add UI using ImGui, similar to the Flatbuffers example I wrote before. Let’s see the three different construct we can output with our language.
Enum
We defined an enum as a name and a list of named values. For the simplicity of this example, we are not assigning manual values to the enum, but it is something easily changeable, and I will do it in the future. Given the enum in HDF:
enum BlendOperation : byte { Add, Subtract, RevSubtract, Min, Max }
Which code do we want to generate ?
When I write enums, I almost always need the stringed version of the values. Also I want to add a last value, Count, so that I can use it if I need to allocate anything based on the enum. As a bonus, I can create a second enum with the bit shifts — called mask — for some use cases. All of this will be automatically done by the code generator, starting with a simple enum! In this piece of code, I will use three different streams for the different parts of the enum (enum itself, value names and mask) and combine them into the final generated file. Also to note that the strings here are ‘String Ref’ — basically a string that points to the input source code and stores the length of the string, so that there is no need to allocate it newly. I will use a temporary buffer to null terminate it and write into the output file.
This will be the generated code:
namespace BlendOperation {
enum Enum {
Add, Subtract, RevSubtract, Min, Max, Count
};
enum Mask {
Add_mask = 1 << 0, Subtract_mask = 1 << 1, RevSubtract_mask = 1 << 2, Min_mask = 1 << 3, Max_mask = 1 << 4, Count_mask = 1 << 5
};
static const char* s_value_names[] = {
"Add", "Subtract", "RevSubtract", "Min", "Max", "Count"
};
static const char* ToString( Enum e ) {
return s_value_names[(int)e];
}
} // namespace BlendOperation
The enum itself (inside a namespace), a mask and the string version for debugging purposes. All generated from that one line!
Let’s go into a step by step review of the code. First there is the initialization of some auxiliary buffers to handle dynamic strings without allocating memory. These are the usages:
- Values will contain all the enum comma separated values
- Value_names will contain the string version of the values
- Value_masks will contain an optional bitmask for the values.
void outputCPPEnum( CodeGenerator* code_generator, FILE* output, const ast::Type& type ) {
// Empty enum: skip output.
if ( type.names.size() == 0 )
return;
code_generator->string_buffer_0.clear();
code_generator->string_buffer_1.clear();
code_generator->string_buffer_2.clear();
StringBuffer& values = code_generator->string_buffer_0;
StringBuffer& value_names = code_generator->string_buffer_1;
StringBuffer& value_masks = code_generator->string_buffer_2;
We start by adding the character ‘"’ in the names - they will be C strings! Then we have a couple of options, just as demonstration: add mask (for the bitmask) and add max, that adds a last element to the generated enum.
value_names.append( "\"" );
bool add_max = true;
bool add_mask = true;
Next step is the core: go through all the names saved in the enum ast::Type during the parsing phase, and add the literal as is in the enum, the literal in string version and optional mask. We also need to take care of the enum with 1 values, they behave in a different way.
char name_buffer[256];
// Enums with more than 1 values
if ( type.names.size() > 1 ) {
const uint32_t max_values = type.names.size() - 1;
for ( uint32_t v = 0; v < max_values; ++v ) {
if ( add_mask ) {
value_masks.append( type.names[v] );
value_masks.append( "_mask = 1 << " );
value_masks.append( _itoa( v, name_buffer, 10 ) );
value_masks.append( ", " );
}
values.append( type.names[v] );
values.append( ", " );
value_names.append( type.names[v] );
value_names.append( "\", \"" );
}
if ( add_mask ) {
value_masks.append( type.names[max_values] );
value_masks.append( "_mask = 1 << " );
value_masks.append( _itoa( max_values, name_buffer, 10 ) );
}
values.append( type.names[max_values] );
value_names.append( type.names[max_values] );
value_names.append( "\"" );
}
else {
if ( add_mask ) {
value_masks.append( type.names[0] );
value_masks.append( "_mask = 1 << " );
value_masks.append( _itoa( 0, name_buffer, 10 ) );
}
values.append( type.names[0] );
value_names.append( type.names[0] );
value_names.append( "\"" );
}
After writing all the values we can add the optional max value in the output:
if ( add_max ) {
values.append( ", Count" );
value_names.append( ", \"Count\"" );
if ( add_mask ) {
value_masks.append( ", Count_mask = 1 << " );
value_masks.append( _itoa( type.names.size(), name_buffer, 10 ) );
}
}
Until now we just saved all those values in the StringBuffers, but still not in the file. The final piece of code output to file the enum with all the additional data:
copy( type.name, name_buffer, 256 );
fprintf( output, "namespace %s {\n", name_buffer );
fprintf( output, "\tenum Enum {\n" );
fprintf( output, "\t\t%s\n", values.data );
fprintf( output, "\t};\n" );
// Write the mask
if ( add_mask ) {
fprintf( output, "\n\tenum Mask {\n" );
fprintf( output, "\t\t%s\n", value_masks.data );
fprintf( output, "\t};\n" );
}
// Write the string values
fprintf( output, "\n\tstatic const char* s_value_names[] = {\n" );
fprintf( output, "\t\t%s\n", value_names.data );
fprintf( output, "\t};\n" );
fprintf( output, "\n\tstatic const char* ToString( Enum e ) {\n" );
fprintf( output, "\t\treturn s_value_names[(int)e];\n" );
fprintf( output, "\t}\n" );
fprintf( output, "} // namespace %s\n\n", name_buffer );
}
Struct
Structs are the bread-and-butter of data definition. In this simple example we do not handle pointers or references, so it is pretty straight-forward, but as a start in coding generation this could already be powerful for many cases. Let’s start with a definition for our dream Data-Driven-Rendering:
// file.hdf
struct RenderTarget {
uint16 width;
uint16 height;
float scale_x;
float scale_y;
TextureFormat format;
};
struct RenderPass {
RenderTarget rt0;
};
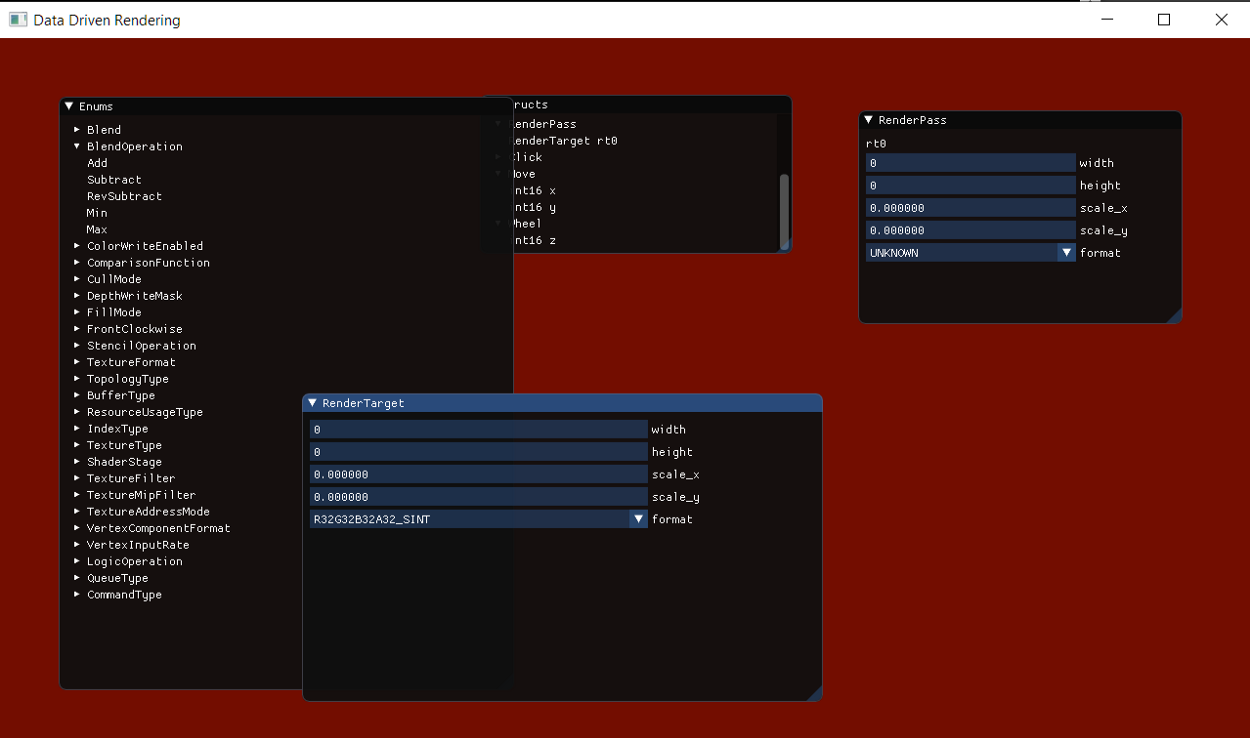
We want to generate both the ready to use header in C++ and UI using ImGui. The output for this struct will be obtained by simply iterating through all its members and, based on the type of the member, write some code. For primitive types there is a translation that must be done to the C++ language — thus we saved a list of c++ primitive types keyword into the code. For the UI area we will define two methods: reflectMembers, that simply adds the ImGui commands needed, and reflectUI, that embeds the members into a Window. This is done so that when starting from a root type I can create a window that let me edit its value, and recursively it can add other member’s UI if they are coming from another struct. This is shown with the RenderPass struct.
This will be the generated code, that includes ImGui too:
// CodeGenerated.h
struct RenderTarget {
uint16_t width;
uint16_t height;
float scale_x;
float scale_y;
TextureFormat::Enum format;
void reflectMembers() {
ImGui::InputScalar( "width", ImGuiDataType_U16, &width );
ImGui::InputScalar( "height", ImGuiDataType_U16, &height );
ImGui::InputScalar( "scale_x", ImGuiDataType_Float, &scale_x );
ImGui::InputScalar( "scale_y", ImGuiDataType_Float, &scale_y );
ImGui::Combo( "format", (int32_t*)&format, TextureFormat::s_value_names, TextureFormat::Count );
}
void reflectUI() {
ImGui::Begin("RenderTarget");
reflectMembers();
ImGui::End();
}
}; // struct RenderTarget
Now let’s have a look at the code that will generate that. First some init steps: clear and alias the StringBuffer, allocate some char buffers on the stack, copy the StringRef into the name buffer:
void outputCPPStruct( CodeGenerator* code_generator, FILE* output, const ast::Type& type ) {
const char* tabs = "";
code_generator->string_buffer_0.clear();
StringBuffer& ui_code = code_generator->string_buffer_0;
char name_buffer[256], member_name_buffer[256], member_type_buffer[256];
copy( type.name, name_buffer, 256 );
Next is already a powerful piece of code. Outputting the UI code and iterating through each member.
if ( code_generator->generate_imgui ) {
ui_code.append( "\n\tvoid reflectMembers() {\n" );
}
fprintf( output, "%sstruct %s {\n\n", tabs, name_buffer );
for ( int i = 0; i < type.types.size(); ++i ) {
const ast::Type& member_type = *type.types[i];
const StringRef& member_name = type.names[i];
copy( member_name, member_name_buffer, 256 );
We are in the middle of the loop, and we want to check if the current member type is a primitive one, then it needs some work to do. First, output the language specific primitive type keyword (using the s_primitive_type_cpp array). Second, add some ImGui code to edit the field directly.
// Translate type name based on output language.
switch ( member_type.type ) {
case ast::Type::Types_Primitive:
{
strcpy_s( member_type_buffer, 256, s_primitive_type_cpp[member_type.primitive_type] );
fprintf( output, "%s\t%s %s;\n", tabs, member_type_buffer, member_name_buffer );
if ( code_generator->generate_imgui ) {
switch ( member_type.primitive_type ) {
case ast::Type::Primitive_Int8:
case ast::Type::Primitive_Uint8:
case ast::Type::Primitive_Int16:
case ast::Type::Primitive_Uint16:
case ast::Type::Primitive_Int32:
case ast::Type::Primitive_Uint32:
case ast::Type::Primitive_Int64:
case ast::Type::Primitive_Uint64:
case ast::Type::Primitive_Float:
case ast::Type::Primitive_Double:
{
ui_code.append( "\t\tImGui::InputScalar( \"%s\", %s, &%s );\n", member_name_buffer, s_primitive_type_imgui[member_type.primitive_type], member_name_buffer );
break;
}
case ast::Type::Primitive_Bool:
{
ui_code.append( "\t\tImGui::Checkbox( \"%s\", &%s );\n", member_name_buffer, member_name_buffer );
break;
}
}
}
break;
}
In case of a struct as a member, use the typename as is and call the ‘reflectMembers’ method for the UI generation:
case ast::Type::Types_Struct:
{
copy( member_type.name, member_type_buffer, 256 );
fprintf( output, "%s\t%s %s;\n", tabs, member_type_buffer, member_name_buffer );
if ( code_generator->generate_imgui ) {
ui_code.append( "\t\tImGui::Text(\"%s\");\n", member_name_buffer );
ui_code.append( "\t\t%s.reflectMembers();\n", member_name_buffer );
}
break;
}
For enums use the format namespace::Enum that comes with the generated code (and can be anything else) and add a Combo for ImGui. The combo is using the string array generated previously! This is powerful!
case ast::Type::Types_Enum:
{
copy( member_type.name, member_type_buffer, 256 );
fprintf( output, "%s\t%s::Enum %s;\n", tabs, member_type_buffer, member_name_buffer );
if ( code_generator->generate_imgui ) {
ui_code.append( "\t\tImGui::Combo( \"%s\", (int32_t*)&%s, %s::s_value_names, %s::Count );\n", member_name_buffer, member_name_buffer, member_type_buffer, member_type_buffer );
}
break;
}
To finish up simlpy add the reflectUI method, that embed the members reflection in a window and finish.
default:
{
break;
}
}
}
ui_code.append( "\t}" );
ui_code.append( "\n\n\tvoid reflectUI() {\n\t\tImGui::Begin(\"%s\");\n\t\treflectMembers();\n\t\tImGui::End();\n\t}\n", name_buffer );
fprintf( output, "%s\n", ui_code.data );
fprintf( output, "\n%s}; // struct %s\n\n", tabs, name_buffer );
}
Command
I wanted to include an example of something that does not exist in any language, but it shows the power of removing boilerplate code.
I define commands as little structs with a type used anytime I need to do some command parsing, normally from a ring buffer.
The command should have an enum with all the types already, and each struct should have its type assigned. The type is normally used to cycle through the commands and do something accordingly.
It will output structs because of the need to allocate them in the ring buffer, thus must be simple.
First let’s see the HDF file. The example are window events commands:
command WindowEvents {
Click {
int16 x;
int16 y;
int16 button;
}
Move {
int16 x;
int16 y;
}
Wheel {
int16 z;
}
};
The generated code will be:
namespace WindowEvents {
enum Type {
Type_Click, Type_Move, Type_Wheel
};
struct Click {
int16_t x;
int16_t y;
int16_t button;
static Type GetType() { return Type_Click; }
}; // struct Wheel
struct Move {
int16_t x;
int16_t y;
static Type GetType() { return Type_Move; }
}; // struct Wheel
struct Wheel {
int16_t z;
static Type GetType() { return Type_Wheel; }
}; // struct Wheel
}; // namespace WindowEvents
And finally the C++ code that generates the output. The output starts with an enum with all the types, that I normally use to switch commands:
void outputCPPCommand( CodeGenerator* code_generator, FILE* output, const ast::Type& type ) {
char name_buffer[256], member_name_buffer[256], member_type_buffer[256];
copy( type.name, name_buffer, 256 );
fprintf( output, "namespace %s {\n", name_buffer );
// Add enum with all types
fprintf( output, "\tenum Type {\n" );
fprintf( output, "\t\t" );
for ( int i = 0; i < type.types.size() - 1; ++i ) {
const ast::Type& command_type = *type.types[i];
copy( command_type.name, name_buffer, 256 );
fprintf( output, "Type_%s, ", name_buffer );
}
const ast::Type* last_type = type.types[type.types.size() - 1];
copy( last_type->name, name_buffer, 256 );
fprintf( output, "Type_%s", name_buffer );
fprintf( output, "\n\t};\n\n" );
Then we output all the command structs (like Click, Move, …). For each command type we output a struct with all its members. This is similar to the output of the structs:
const char* tabs = "\t";
for ( int i = 0; i < type.types.size(); ++i ) {
const ast::Type& command_type = *type.types[i];
copy( command_type.name, member_type_buffer, 256 );
fprintf( output, "%sstruct %s {\n\n", tabs, member_type_buffer );
for ( int i = 0; i < command_type.types.size(); ++i ) {
const ast::Type& member_type = *command_type.types[i];
const StringRef& member_name = command_type.names[i];
copy( member_name, member_name_buffer, 256 );
// Translate type name based on output language.
switch ( member_type.type ) {
case ast::Type::Types_Primitive:
{
strcpy_s( member_type_buffer, 256, s_primitive_type_cpp[member_type.primitive_type] );
fprintf( output, "%s\t%s %s;\n", tabs, member_type_buffer, member_name_buffer );
break;
}
case ast::Type::Types_Struct:
{
copy( member_type.name, member_type_buffer, 256 );
fprintf( output, "%s\t%s %s;\n", tabs, member_type_buffer, member_name_buffer );
break;
}
case ast::Type::Types_Enum:
{
copy( member_type.name, member_type_buffer, 256 );
fprintf( output, "%s\t%s::Enum %s;\n", tabs, member_type_buffer, member_name_buffer );
break;
}
default:
{
break;
}
}
}
copy( command_type.name, member_type_buffer, 256 );
fprintf( output, "\n%s\tstatic Type GetType() { return Type_%s; }\n", tabs, member_type_buffer );
fprintf( output, "\n%s}; // struct %s\n\n", tabs, name_buffer );
}
copy( type.name, name_buffer, 256 );
fprintf( output, "}; // namespace %s\n\n", name_buffer );
}
Conclusions
We learnt how to write a complete Code Generator, an incredible tool that can speed up the development if used correctly and remove most boilerplate code possible.
The usage of the command keyword was an example of something I use and I don’t want to write code, something that is custom enough and hopefully will give you more ideas on how you can break free from languages constriction when you write…your own language!
In the quest for data-driven rendering, the next step will be to use the knowledge from code generation to create a shader effect language, that can generate both CPU and GPU code for you.
This article is the longest and more code-heavy I have ever written. There are many concepts that I am beginning to be familiar with, but still not so used to.
So please comment, give feedback, share! Thank you for reading!