Overview
Data Driven Rendering Series:
- https://jorenjoestar.github.io/post/writing_shader_effect_language_1/
- https://jorenjoestar.github.io/post/writing_shader_effect_language_2/
- https://jorenjoestar.github.io/post/writing_shader_effect_language_3/
- https://jorenjoestar.github.io/post/data_driven_rendering_pipeline/
In Part 1 of this series we created a simple language to work as ‘shader effect’ - a shader language superset to make our life easier, by adding missing features. The fact that there is not an industry standard for a shader effect language leads to either hand-crafted (and secret) languages, or to hardcoded permutations, or to other gray-area solutions.
(Personal though: part of me would like to help in contributing to the creation of a standard through these articles and code.)
What is the goal of this article ?
The goal is to enrich the HFX language to generate more code possible and/or bake data for us, namely:
- Shader constants generation
- Shader resource bindings
- Render states (depth stencil, blend, rasterization)
- Render pass hints for a future framegraph
We will see Render States and Render Pass hints in a following article, because this is an already lengthy article!
I hope that by now the way of adding an identifier, parsing it and generating code is clearer. In this article we will focus more on the features than anything else, even though I will put a lot of code still. But before that, we need to have a big addition to our example: a rendering API! We will use this as target of our code generation, and it will be an amazing example to see something working.
Maybe this will spark a new FX Composer ?
This article will be divided in 2 parts. Part 1 of this article will talk about the rendering API. Part 2 will be about the extended HFX language. If you are not interested in that, jump to part 2 of this article.
Part 1: adding a low-level rendering API
Writing articles on rendering without some sort of API to use is tricky. Creating a language to speed up data driven rendering, either for generating code and/or for baking data needs a target API. The main idea is to have an abstract API to map more easily rendering concepts instead of losing ourselves in specific API needs.
The search for an abstract API
The first thing to do is to search for an existing abstract API. I have few criteria in mind:
- Simple and clear interface
- Compact and clear code
- Vulkan and D3D12 interface
With those in mind, I found 2 alternatives: BGFX and Sokol.
I am an honest fan of both, they are brilliant, robust and well written. But for the purpose of these articles, sadly they miss my search criteria. There is also a huge disclaimer here: I used them too little, so it is possible I overlooked the usage of them. I will be more than glad to use either instead of my toy API! I respect the developers and the library a lot, they are doing an amazing job! But we are handcrafting something, and to properly do that I personally need to know deeply the code. And I am not.
BGFX is very complete, but the interface is a little confusing for me, possibly because I never used it but just read the code few times. The main reason I chose not to use it is because the interface is missing the resource interface like Vulkan and D3D12 (DescriptorSets, …), otherwise it would have been an amazing choice.
Sokol is also very good, I love the code and the simple interface. Two main problems here: again no Vulkan/D3D12 resource interface, and in this case a different target: it does not support compute shaders.
Again, I want to make it clear: I am not saying these are not good libraries. They are amazing. They just don’t fit my search criteria, plus I LOVE to work on rendering architecture. Well actually, it is my favourite job!
So kudos to them (I also wrote to Andre Weissflog to ask for compute shader support, but it is not in his plans for now) but we are making a different choice.
If you ever find anything that I write useful guys, please let me know!
Hydra Graphics: design principles
Small trivia: the name comes from my first ever graphics engine written in 2006 (I think), after devouring 3D Game Engine Design by Dave Eberly. I already knew I would write many engines and I would learn and grow stronger from every of them, so I chose the name Hydra from the Greek mythology monster. The other name would have been Phoenx engine, but I remember finding already some tech with that name.
Anyway, design principles! I really loved the interface of Sokol, and often I used something similar by myself. I opted for a pair of header/implementation files as the only needed files.
The backend is OpenGL for now, just because I have a working implementation in my indie project that works with pretty complex rendering, and I can use that as reference.
Interface
Rendering in general is a matter of creating, modifying and combining resources. There are mainly 2 classes that do all the rendering work:
- Device
- Command Buffer
The Device is responsible for creation, destruction, modification and query of the resources. The Command Buffer is responsible for the usage of resources for rendering.
The obvious fundamental concept is resource. A resource is handled externally through handles, can be created using creation structs and has both a common and an API-specific representation.
Buffers are specialized in vertex/index/constant/… depending on their creation parameters.
This is a small example on creation/usage/destruction of a resource. First, we can create a texture:
graphics::TextureCreation first_rt = {};
first_rt.width = 512;
first_rt.height = 512;
first_rt.render_target = 1;
first_rt.format = graphics::TextureFormat::R8G8B8A8_UNORM;
TextureHandle render_target = gfx_device.create_texture( first_rt );
Next we can create a command buffer:
CommandBuffer* commands = gfx_device.get_command_buffer( graphics::QueueType::Graphics, 1024 );
Skipping other creations, we bind resources and add the commands:
commands->bind_pipeline( first_graphics_pipeline );
commands->bind_resource_set( gfx_resources );
commands->bind_vertex_buffer( gfx_device.get_fullscreen_vertex_buffer() );
commands->draw( graphics::TopologyType::Triangle, 0, 3 );
At this point we can execute the command buffer to draw.
gfx_device.execute_command_buffer( commands );
Updating a resource can be done like that:
hydra::graphics::MapBufferParameters map_parameters = { buffer.handle, 0, 0 };
LocalConstants* buffer_data = (LocalConstants*)device.map_buffer( map_parameters );
Everything uses structs to perform creation/updates. Nothing new, but I always loved this design.
Resource layout and resource lists
I wanted to bring the Vulkan/D3D12 resource interface as first class citizens, and remove completely old concepts (like single constants, render states as single objects, single bind of a resource) and add new ones: resource layout, resource lists and command buffers. Well command buffers are not new, but finally you can draw only with those!
In Vulkan/D3D12 you can bind resources through the usage of sets: basically tables that contains the resources used. This is a welcomed difference from previous APIs, and I think it is a concept not too hard to grasp but very useful to have it explicit.
The first thing to define is the resource layout describes the layout of a set of resources. For example, if we have a material that uses Albedo and Normals textures and a constant buffer, the layout will contain all the informations about that (like the type, the GPU registers and so on). This though still does not contain the resources themselves! Enter resource list. A resource list is a list of actual resources relative to a layout. It sets resources using a layout.
From now on, when we draw we can bind one or more resource lists.
In Vulkan lingo, the resource layout is called descriptor set layout, and a resource list is a descriptor set. Here are a couple of articles for the Vulkan side:
Official Vulkan Documentation on Descriptor Layouts and Sets
Intel API Without Secrets Part 6
Similarly in D3D12 there are Root Tables and Descriptor Tables. The concepts do no map 1 to 1 but they are pretty similar:
I tried to map these concepts using different words that would make more sense to me, so from Descriptor Set or Root Table it became Resource List and Resource Layout.
Pipelines
Finally a pipeline is the complete description of what is needed by the GPU to draw something on the screen (or to use a Compute Shader for any other purpose). Basically a pipeline must fill all the informations for all the GPU stages like this (thanks to RenderDoc):

RenderDoc Pipeline
What once was setup individually now is all in one place (reflecting what happened behind the scene, into the driver). DepthStencil, AlphaBlend, Rasterization, Shaders, all must be defined here.
In the currrent implementation of the graphics-API a lot of states are still missing!.
Now that we say the basic principles of the target rendering API, we can finally concentrate on the new freatures of HFX.
Part 2: forging the HFX language features
Our HFX language needs some properties to be added but first there is a change: HFX will generate a binary version to embed all the informations needed to create a shader.
HFX evolution: what files are generated ?
In the previous article, we used a single HFX file to generate multiple glsl files, ready to be used by any OpenGL renderer:
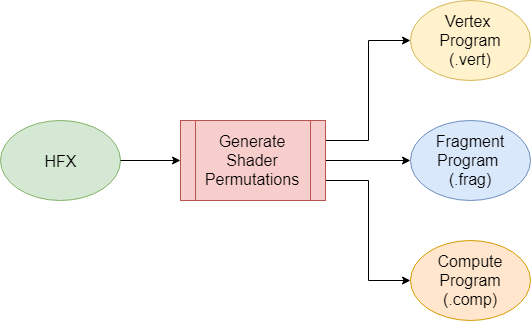
Shader Generation
Remembering the article on Hydra Data Format, we instead were generating an header file. For our needs, we will generate an embedded HFX (binary HFX) AND a C++ header:
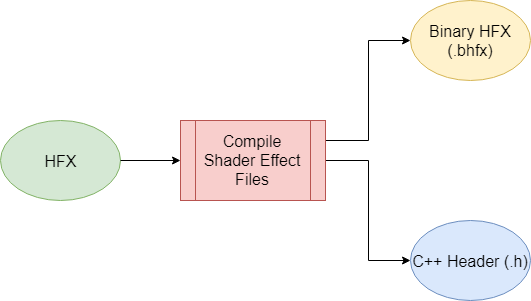
Binary and Header Generation
What is the next step for HFX ? For shader generation, we want ideally to load a HFX file without having to manually stick together the single shader files, and that is why the first step is to create embedded HFX files. This will contain all the information to create a shader, and this includes also the resource layouts.
For constant handling, we want to have UI generated and easy update on the gpu. We want to automate these things. This can be done in a more code-generated way or by generating data.
If we abstract the problem, all these articles are about understanding how you want to generate code or data to maximise iteration time, performances and control. By moving the HFX to being binary, we are effectively generating data used by the renderer. For the shader UI, we can do both: generate code or create data. We will see the generated code part here.
Let’s see briefly the internals of the Embedded HFX file format:
Embedded HFX
As a Recap, when parsing HFX we store some informations.
First is the CodeFragment, including also (spoiler!) the addition of resources for the sake of this article:
// C++
//
struct CodeFragment {
struct Resource {
hydra::graphics::ResourceType::Enum type;
StringRef name;
}; // struct Resource
std::vector<StringRef> includes;
std::vector<Stage> includes_stage; // Used to separate which include is in which shader stage.
std::vector<Resource> resources; // Used to generate the layout table.
StringRef name;
StringRef code;
Stage current_stage = Stage::Count;
uint32_t ifdef_depth = 0;
uint32_t stage_ifdef_depth[Stage::Count];
}; // struct CodeFragment
The rest is unchanged from the previous article. We have basically code and includes to bake the final shader. Remember, we are handling GLSL in these examples!
Next is the Pass:
// C++
//
struct Pass {
StringRef name;
struct ShaderStage {
const CodeFragment* code = nullptr;
Stage stage = Stage::Count;
}; // struct ShaderStage
StringRef name;
std::vector<ShaderStage> shader_stages;
}; // struct Pass
Nothing changed here. A pass is a container of one of more shaders. In general we will use the term shader state to describe the shaders that needs to be bound to the pipeline. Most common are the couple Vertex and Fragment shaders, or the Compute by itself.
Last is the Shader itself:
// C++
//
struct Shader {
StringRef name;
std::vector<Pass*> passes;
std::vector<Property*> properties;
}; // struct Shader
Being just a collection of passes. Again we are seeing the properties here, that I will talk later on in the article.
These will be used to ‘bake’ data into a ‘bhfx’ (binary HFX) file.
BHFX layout
In order to maximise efficiency, we are packing the data in the way we will use it. The file is divided in two main sections: common and passes. The overall layout is as follows:
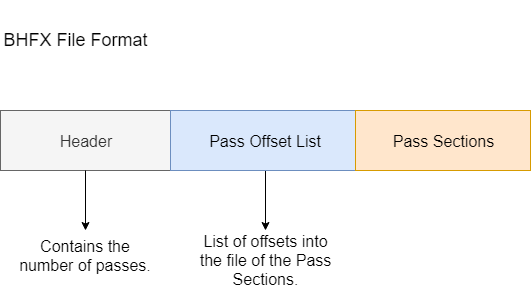
The trick is to have the offset for each section easy to access.
The pass section contains several informations as following:
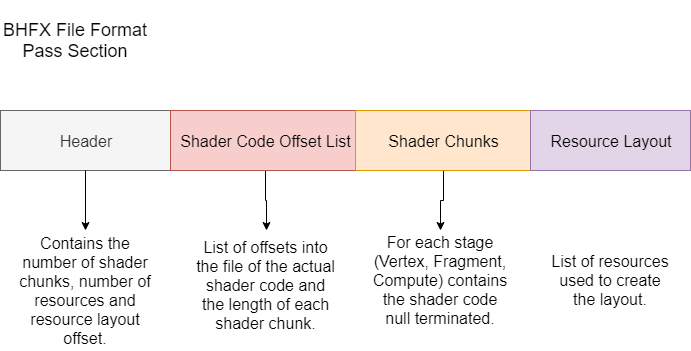
As we will see later we include shaders, resources layout and other data based on our target API (Hydra Graphics).
Writing the BHFX file
To write our file, we need to parse the HFX file. A quick code could be something like this:
// C++
//
...
char* text = ReadEntireFileIntoMemory( "..\\data\\SimpleFullscreen.hfx", nullptr );
initLexer( &lexer, (char*)text, data_buffer );
hfx::initParser( &effect_parser, &lexer );
hfx::generateAST( &effect_parser );
hfx::initCodeGenerator( &hfx_code_generator, &effect_parser, 4096, 5 );
hfx::compileShaderEffectFile( &hfx_code_generator, "..\\data\\", "SimpleFullscreen.bhfx" );
Here we are parsing the file (generateAST) and then using that to compile our shader effect file. This is where the magic happens.
// C++
//
void compileShaderEffectFile( CodeGenerator* code_generator, const char* path, const char* filename ) {
// Create the output file
FILE* output_file;
// Alias the StringBuffer for better readability.
StringBuffer& filename_buffer = code_generator->string_buffers[0];
// Concatenate name
filename_buffer.clear();
filename_buffer.append( path );
filename_buffer.append( filename );
fopen_s( &output_file, filename_buffer.data, "wb" );
if ( !output_file ) {
printf( "Error opening file. Aborting. \n" );
return;
}
Typical file creation preamble. Concatenate the file using the StringBuffer, and try to create it.
Remember that overall the file structure is:
- File header
- Pass offset list
- Pass sections
Let’s start with the file header:
const uint32_t pass_count = (uint32_t)code_generator->parser->passes.size();
ShaderEffectFile shader_effect_file;
shader_effect_file.num_passes = pass_count;
fwrite( &shader_effect_file, sizeof(ShaderEffectFile), 1, output_file );
In this case we are writing straight to the file, because it is an in-order operation with the file layout. For the rest of the file writing we will need to use String Buffers to accumulate data out-of-order and then write the file in the correct order. Think of the Pass Offset List: to calculate the offsets we need to know the size of the passes. To know the size we need to finalize the pass data. To finalize the pass data we need to finalize shaders, and that means adding the includes.
Again for code clarity I use aliases like this:
StringBuffer& code_buffer = code_generator->string_buffers[1];
StringBuffer& pass_offset_buffer = code_generator->string_buffers[2];
StringBuffer& shader_offset_buffer = code_generator->string_buffers[3];
StringBuffer& pass_buffer = code_generator->string_buffers[4];
Let’s continue. We start tracking the pass section memory offset knowing that it will be after the header and the pass offset list:
pass_offset_buffer.clear();
pass_buffer.clear();
// Pass memory offset starts after header and list of passes offsets.
uint32_t pass_offset = sizeof( ShaderEffectFile ) + sizeof(uint32_t) * pass_count;
Now into the most interesting part. We will avoid talking about the resource layout part, that will be added later.
// Pass Section:
// ----------------------------------------------------------------------------------------
// Shaders count | Name | Shader Offset+Count List | Shader Code 0, Shader Code 1
// ----------------------------------------------------------------------------------------
ShaderEffectFile::PassHeader pass_header;
for ( uint32_t i = 0; i < pass_count; i++ ) {
pass_offset_buffer.append( &pass_offset, sizeof( uint32_t ) );
const Pass& pass = code_generator->parser->passes[i];
const uint32_t pass_shader_stages = (uint32_t)pass.shader_stages.size();
const uint32_t pass_header_size = pass_shader_stages * sizeof( ShaderEffectFile::Chunk ) + sizeof( ShaderEffectFile::PassHeader );
uint32_t current_shader_offset = pass_header_size;
We start iterating the passes and calculate the shader offset. Shader Chunks (the actual shader code) are written after the Pass Header and the dynamic list of shader chunk offset and size. Next we will calculate the offsets of the single shaders AFTER we finalize the code - that means after the includes are added!
shader_offset_buffer.clear();
code_buffer.clear();
for ( size_t s = 0; s < pass.shader_stages.size(); ++s ) {
const Pass::ShaderStage shader_stage = pass.shader_stages[s];
appendFinalizedCode( path, shader_stage.stage, shader_stage.code, filename_buffer, code_buffer, true, constants_buffer );
updateOffsetTable( ¤t_shader_offset, pass_header_size, shader_offset_buffer, code_buffer );
}
// Update pass offset
pass_offset += code_buffer.current_size + shader_offset;
At this point we have code_buffer containing all the shaders of the pass one after another (null terminated) and we can update the pass offset for the next pass. We also calculated the single shader offsets with the updateOffsetTable method in shader_offset_buffer. We need to finalize the Pass Header and then we can merge the pass memory in one block and proceed to the next pass:
// Fill Pass Header
copy( pass.name, pass_header.name, 32 );
pass_header.num_shader_chunks = pass.num_shaders;
This is a very IMPORTANT part. Merge in the pass_buffer all the pass section currently calculated: pass header, the single shader code offsets and the shader code itself.
pass_buffer.append( (void*)&pass_header, sizeof( ShaderEffectFile::PassHeader ) );
pass_buffer.append( shader_offset_buffer );
pass_buffer.append( code_buffer );
}
After we finished with all the passes, we have 2 buffers: one containing the pass offset list, the other the pass sections. We can write them off in the correct order finally and close the file:
fwrite( pass_offset_buffer.data, pass_offset_buffer.current_size, 1, output_file );
fwrite( pass_buffer.data, pass_buffer.current_size, 1, output_file );
fclose( output_file );
}
We can see why we chose this format when looking at the code to actually create a shader state. First of all this is the struct to create a shader state:
// hydra_graphics.h
//
struct ShaderCreation {
struct Stage {
ShaderStage::Enum type = ShaderStage::Compute;
const char* code = nullptr;
}; // struct Stage
const Stage* stages = nullptr;
const char* name = nullptr;
uint32_t stages_count = 0;
}; // struct ShaderCreation
It is very simple, each stage has a code and type. A shader state can have one or more stages. This was already the case in OpenGL - compiling shaders and linking them - so the interface is similar - but it maps well to Vulkan/D3D12 as well, in which the Pipeline State, that describe almost everything the GPU needs to draw, needs an unique set of vertex/fragment/compute shaders. Anyway, we embed this data already in the binary HFX file, and thus we can easily create a shader state like this:
static void compile_shader_effect_pass( hydra::graphics::Device& device, char* hfx_memory,
uint16_t pass_index, hydra::graphics::ShaderHandle& out_shader ) {
using namespace hydra;
// Get pass section memory
char* pass = hfx::getPassMemory( hfx_memory, pass_index );
hfx::ShaderEffectFile::PassHeader* pass_header = (hfx::ShaderEffectFile::PassHeader*)pass;
const uint32_t shader_count = pass_header->num_shader_chunks;
graphics::ShaderCreation::Stage* stages = new graphics::ShaderCreation::Stage[shader_count];
// Get individual shader code and type
for ( uint16_t i = 0; i < shader_count; i++ ) {
hfx::getShaderCreation( shader_count, pass, i, &stages[i] );
}
graphics::ShaderCreation first_shader = {};
first_shader.stages = stages;
first_shader.stages_count = shader_count;
first_shader.name = pass_header->name;
out_shader = device.create_shader( first_shader );
delete stages;
}
Nothing really interesting here, but we read the file in memory and use the offsets we store to access the different sections of the file.
To access the Pass Section we first need to read its memory offset and then read from there. Remember from before that the offset is in the list AFTER the ShaderEffectFile header, and it is a single uint32:
char* getPassMemory( char* hfx_memory, uint32_t index ) {
// Read offset form list after the ShaderEffectFile header.
const uint32_t pass_offset = *(uint32_t*)(hfx_memory + sizeof( ShaderEffectFile ) + (index * sizeof( uint32_t )));
return hfx_memory + pass_offset;
}
From the pass offset, the list of shader chunks (that are defined as code offset and size) is right after the pass header
void getShaderCreation( uint32_t shader_count, char* pass_memory, uint32_t index,
hydra::graphics::ShaderCreation::Stage* shader_creation ) {
char* shader_offset_list_start = pass_memory + sizeof( ShaderEffectFile::PassHeader );
Read the single shader offset and access the memory there:
const uint32_t shader_offset = *(uint32_t*)(shader_offset_list_start + (index * sizeof( ShaderEffectFile::Chunk )));
char* shader_chunk_start = pass_memory + shader_offset;
The baked informations are first the type (as a single char, but called hfx::ShaderEffectFile::ChunkHeader in case we change it) and the actual shader code is right after!
shader_creation->type = (hydra::graphics::ShaderStage::Enum)(*shader_chunk_start);
shader_creation->code = (const char*)(shader_chunk_start + sizeof( hfx::ShaderEffectFile::ChunkHeader ));
}
In this case I chose to bake the file instead of generating a header file - just cause I can reuse this code for every shader effect. I could have generated an header instead of the binary BHFX file, but then including it would mean that you need to recompile at every change. We will see some areas in which we can have both approaches!
Finally done with the new embedded format, let’s see the new features!
Brainstorming: what features are needed ?
We already talked about the features at the beginning of the articles, but let’s write them again to refresh our memory:
- Shader constants generation
- Shader resource bindings
- Render states (depth stencil, blend, rasterization) (in the next article)
- Render pass hints for a future framegraph (in the next article)
There are few articles around this subject, but the most complete is from the amazing guys at OurMachinery, and in particular this article. These guys does (as always honestly) an amazing job in describing the problem we are facing and the solutions, and how enriching a shader language can make a huge difference in making better rendering (faster iteration time, less error prone, more artist friendly..) so I would suggest to read those articles (and in general any article/presentation/blog post they write!).
We will go through each feature in depth so get ready!
Constants: artists, programmers, both ?
Constants…uniforms…whatever name you choose, they represent the same concept: numerical properties.
Even if they are a simple concept, still it is hard to make both rendering citizens happy: artists and programmers!
Artists want tweakable UI, simple variables and fast iteration. Programmers want optimal layout, more CPU calculated variables possible, and ultimate control. How to make them both happy ?
I brainstormed and designed for few days (well evenings) to solve this problem. One thought that came to me is that artists want to create a material interface, something they can tweak and change easily, and when you want to quickly prototype something, create and such, you don’t want to deal with low-level resource management and such. Let’s solve this first: give artists a simple way of creating a material interface!
After searching for a bit, I chose to use a syntax very similar to Unity ShaderLab. Let’s see the HFX (finally!):
// .HFX
//
// For the artist: create a material interface.
properties {
// Using Unity ShaderLab syntax:
// AORemapMin0("AORemapMin0", Range(0.0, 1.0)) = 0.0
scale("Scale", Float) = 32.00
modulo("Modulo", Float) = 2.0
}
We added a new section in the language, named “properties”. Why this name ? Because properties contains both numerical properties and textures! The name makes sense in this way. Naming ‘constants’ and having also textures, not.
There are 2 possible outputs from this, one that is pure code-generation and the other that is more data-driven. I will dwelve into the code-generation one and talk about the data-driven one in another post.
There are 3 parts for the generated code of the properties:
- Properties UI
- GPU-ready constant buffer
- API-dependant buffer
For the Properties UI, we want to generate something like this:
// C++
struct LocalConstantsUI {
float scale = 32.000000f;
float modulo = 2.000000f;
void reflectMembers() {
ImGui::InputScalar( "Scale", ImGuiDataType_Float, &scale);
ImGui::InputScalar( "Modulo", ImGuiDataType_Float, &modulo);
}
void reflectUI() {
ImGui::Begin( "LocalConstants" );
reflectMembers();
ImGui::End();
}
}; // struct LocalConstantsUI
For the GPU-ready constants, we want to have a both a GPU and a CPU representation like this:
// C++
//
struct LocalConstants {
float scale = 32.000000f;
float modulo = 2.000000f;
float pad_tail[2];
}; // struct LocalConstants
// GLSL
//
layout (std140, binding=7) uniform LocalConstants {
float scale;
float modulo;
float pad[2];
} local_constants;
And for the API-dependant buffer, we want to create code that takes care of everything for us. This is the real deal here - and something we will revisit in next articles to show some advanced features.
void create( hydra::graphics::Device& device ) {
using namespace hydra;
graphics::BufferCreation constants_creation = {};
constants_creation.type = graphics::BufferType::Constant;
constants_creation.name = "LocalConstants";
constants_creation.usage = graphics::ResourceUsageType::Dynamic;
// NOTE: using LocalConstants struct - is the GPU ready one with padding and such!
constants_creation.size = sizeof( LocalConstants );
// Struct is initialized with default values already, so it is safe to copy it to the GPU.
constants_creation.initial_data = &constants;
buffer = device.create_buffer( constants_creation );
}
void destroy( hydra::graphics::Device& device ) {
device.destroy_buffer( buffer );
}
void updateUI( hydra::graphics::Device& device ) {
// Draw UI
constantsUI.reflectUI();
// TODO:
// Ideally there should be a way to tell if a variable has changed and update only in that case.
// Map buffer to GPU and upload parameters from the UI
hydra::graphics::MapBufferParameters map_parameters = { buffer.handle, 0, 0 };
LocalConstants* buffer_data = (LocalConstants*)device.map_buffer( map_parameters );
if ( buffer_data ) {
buffer_data->scale = constantsUI.scale;
buffer_data->modulo = constantsUI.modulo;
device.unmap_buffer( map_parameters );
}
}
For the sake of the example this could be a possible implementation - but really depends on the rendering API. Let’s quickly check parsing and code-generation.
Constants Parsing
To parse the new property section, there is the new method void declarationProperties( Parser* parser ) that iterates through all properties, and inside that the void declarationProperty( Parser* parser, const StringRef& name ) one.
We are parsing the following HFX syntax:
// Syntax
//
identifier(string, identifier[(arguments)]) [= default_value]
With this is an example:
// HFX
//
properties {
scale("Scale", Float) = 32.0
}
We will add a simple backtracking to the parsing because of the optional parameters. Let’s check the code!
inline void declarationProperty( Parser* parser, const StringRef& name ) {
Property* property = new Property();
// Cache name
property->name = name;
Token token;
if ( !expectToken( parser->lexer, token, Token::Token_OpenParen ) ) {
return;
}
We just parsed the property name and the ‘(’. Next is the string containing the UI name:
// Advance to the string representing the ui_name
if ( !expectToken( parser->lexer, token, Token::Token_String ) ) {
return;
}
property->ui_name = token.text;
Saved the ui name and then we have the type. Types can be Float, Int, Range, Texture, Vector, Color and we will simply parse their text and convert it to an enum that we will use in the code generation phase.
if ( !expectToken( parser->lexer, token, Token::Token_Comma ) ) {
return;
}
// Next is the identifier representing the type name
if ( !expectToken( parser->lexer, token, Token::Token_Identifier ) ) {
return;
}
// Parse property type and convert it to an enum
property->type = propertyTypeIdentifier( token );
Now will come the most complicated part. We have optional ‘(’ open parenthesis for the parameters if the type needs it. For the length of code and article, I skip this part and will add it in next article!
// If an open parenthesis is present, then parse the ui arguments.
nextToken( parser->lexer, token );
if ( token.type == Token::Token_OpenParen ) {
property->ui_arguments = token.text;
while ( !equalToken( parser->lexer, token, Token::Token_CloseParen ) ) {
// TODO:
// Parse parameters!
}
// Advance to the last close parenthesis
nextToken( parser->lexer, token );
property->ui_arguments.length = token.text.text - property->ui_arguments.text;
}
if ( !checkToken( parser->lexer, token, Token::Token_CloseParen ) ) {
return;
}
At this point we can either be at the end of the property or we could have a ‘=’ token to add a default value. Being that the Lexer class is small, we can backtrack by saving the current Lexer status:
// Cache lexer status and advance to next token.
// If the token is '=' then we parse the default value.
// Otherwise backtrack by one token.
Lexer cached_lexer = *parser->lexer;
Now we can advance to the next token and:
- If the token is ‘=’, parse the default value.
- If not, backtrack the position of the Lexer and finish the parsing.
nextToken( parser->lexer, token );
// At this point only the optional default value is missing, otherwise the parsing is over.
if ( token.type == Token::Token_Equals ) {
nextToken( parser->lexer, token );
if ( token.type = Token::Token_Number ) {
// Cache the data buffer entry index into the property for later retrieval.
property->data_index = parser->lexer->data_buffer->current_entries - 1;
}
else {
// TODO:
// Handle vectors, colors and non single number default values
}
}
else {
*parser->lexer = cached_lexer;
}
parser->shader.properties.push_back( property );
}
An interesting point is that the numbers are parsed in a DataBuffer, and during the parsing of the token we will add the number to it.
To retrieve it, we have the data_index field of the Property struct.
Also here, for the sake of ‘brevity’, I am handling only floats and ints. Vectors, colors and texture property should be easy to add.
For vectors and colors we should parse a list of them and save them into the data buffer.
For textures we should just save the default value as text and use it in the code-generation part.
Code Generation
This should be pretty straight forward. We can iterate the properties and generate both a C++ struct and a HLSL/GLSL buffer. The only thing to be concerned is the padding: on the GPU normally the alignment is 16 bytes, so we can track that and insert padding when generating the code.
In the method void generateShaderResourceHeader( CodeGenerator* code_generator, const char* path ) we can see how we generate the different code for C++:
// C++
//
// Beginning
fprintf( output_file, "\n#pragma once\n#include <stdint.h>\n#include \"hydra_graphics.h\"\n\n// This file is autogenerated!\nnamespace " );
fwrite( shader.name.text, shader.name.length, 1, output_file );
fprintf( output_file, " {\n\n" );
// Preliminary sections
constants_ui.append( "struct LocalConstantsUI {\n\n" );
cpu_constants.append( "struct LocalConstants {\n\n" );
constants_ui_method.append("\tvoid reflectMembers() {\n");
buffer_class.append( "struct LocalConstantsBuffer {\n\n\thydra::graphics::BufferHandle\tbuffer;\n" );
buffer_class.append( "\tLocalConstants\t\t\t\t\tconstants;\n\tLocalConstantsUI\t\t\t\tconstantsUI;\n\n" );
buffer_class.append( "\tvoid create( hydra::graphics::Device& device ) {\n\t\tusing namespace hydra;\n\n" );
buffer_class.append( "\t\tgraphics::BufferCreation constants_creation = { graphics::BufferType::Constant, graphics::ResourceUsageType::Dynamic, sizeof( LocalConstants ), &constants, \"LocalConstants\" };\n" );
buffer_class.append( "\t\tbuffer = device.create_buffer( constants_creation );\n\t}\n\n" );
buffer_class.append( "\tvoid destroy( hydra::graphics::Device& device ) {\n\t\tdevice.destroy_buffer( buffer );\n\t}\n\n" );
buffer_class.append( "\tvoid updateUI( hydra::graphics::Device& device ) {\n\t\t// Draw UI\n\t\tconstantsUI.reflectUI();\n\t\t// Update constants from UI\n" );
buffer_class.append( "\t\thydra::graphics::MapBufferParameters map_parameters = { buffer.handle, 0, 0 };\n" );
buffer_class.append( "\t\tLocalConstants* buffer_data = (LocalConstants*)device.map_buffer( map_parameters );\n\t\tif (buffer_data) {\n" );
// For GPU the struct must be 16 bytes aligned. Track alignment
uint32_t gpu_struct_alignment = 0;
DataBuffer* data_buffer = code_generator->parser->lexer->data_buffer;
// For each property write code
for ( size_t i = 0; i < shader.properties.size(); i++ ) {
hfx::Property* property = shader.properties[i];
switch ( property->type ) {
case Property::Float:
{
constants_ui.append("\tfloat\t\t\t\t\t");
constants_ui.append( property->name );
cpu_constants.append( "\tfloat\t\t\t\t\t" );
cpu_constants.append( property->name );
if ( property->data_index != 0xffffffff ) {
float value = 0.0f;
getData( data_buffer, property->data_index, value );
constants_ui.append( "\t\t\t\t= %ff", value );
cpu_constants.append( "\t\t\t\t= %ff", value );
}
constants_ui.append( ";\n" );
cpu_constants.append( ";\n" );
constants_ui_method.append("\t\tImGui::InputScalar( \"");
constants_ui_method.append( property->ui_name );
constants_ui_method.append( "\", ImGuiDataType_Float, &" );
constants_ui_method.append( property->name );
constants_ui_method.append( ");\n" );
// buffer_data->scale = constantsUI.scale;
buffer_class.append("\t\t\tbuffer_data->");
buffer_class.append( property->name );
buffer_class.append( " = constantsUI." );
buffer_class.append( property->name );
buffer_class.append( ";\n" );
++gpu_struct_alignment;
break;
}
}
}
// Post-property sections
constants_ui.append( "\n" );
constants_ui_method.append( "\t}\n\n" );
constants_ui_method.append( "\tvoid reflectUI() {\n\t\tImGui::Begin( \"LocalConstants\" );\n" );
constants_ui_method.append( "\t\treflectMembers();\n\t\tImGui::End();\n\t}\n\n" );
constants_ui_method.append( "}; // struct LocalConstantsUI\n\n" );
// Add tail padding data
uint32_t tail_padding_size = 4 - (gpu_struct_alignment % 4);
cpu_constants.append( "\tfloat\t\t\t\t\tpad_tail[%u];\n\n", tail_padding_size );
cpu_constants.append( "}; // struct LocalConstants\n\n" );
buffer_class.append( "\t\t\tdevice.unmap_buffer( map_parameters );\n\t\t}\n\t}\n}; // struct LocalConstantBuffer\n\n" );
fwrite( constants_ui.data, constants_ui.current_size, 1, output_file );
fwrite( constants_ui_method.data, constants_ui_method.current_size, 1, output_file );
fwrite( cpu_constants.data, cpu_constants.current_size, 1, output_file );
fwrite( buffer_class.data, buffer_class.current_size, 1, output_file );
// End
fprintf( output_file, "} // namespace " );
fwrite( shader.name.text, shader.name.length, 1, output_file );
fprintf( output_file, "\n\n" );
fclose( output_file );
This piece of code will generate a constant buffer from the properties:
// GLSL
//
static void generateConstantsCode( const Shader& shader, StringBuffer& out_buffer ) {
if ( !shader.properties.size() ) {
return;
}
// Add the local constants into the code.
out_buffer.append( "\n\t\tlayout (std140, binding=7) uniform LocalConstants {\n\n" );
// For GPU the struct must be 16 bytes aligned. Track alignment
uint32_t gpu_struct_alignment = 0;
const std::vector<Property*>& properties = shader.properties;
for ( size_t i = 0; i < shader.properties.size(); i++ ) {
hfx::Property* property = shader.properties[i];
switch ( property->type ) {
case Property::Float:
{
out_buffer.append( "\t\t\tfloat\t\t\t\t\t" );
out_buffer.append( property->name );
out_buffer.append( ";\n" );
++gpu_struct_alignment;
break;
}
}
}
uint32_t tail_padding_size = 4 - (gpu_struct_alignment % 4);
out_buffer.append( "\t\t\tfloat\t\t\t\t\tpad_tail[%u];\n\n", tail_padding_size );
out_buffer.append( "\t\t} local_constants;\n\n" );
}
Expert constants: an interesting problem
A problem many times surfaces is that the material interface does not correspond to the buffer sent to the GPU, because the programmers will do the following:
- Add system constants, that don’t need a UI
- Change order of the constants
- Change constants to more GPU friendly values, calculating some stuff on the CPU
- Pack constants into smaller ones
This is an interesting topic and I’ll cover it in another article, but a simple solution would be to add a mapping between the GPU constants and the UI, so that we can separate the UI constants from the GPU ones.
I’ll give a brief example but it would be too much for this article and will not be included in the source code.
Basically we are trying to create a mapping between the material interface:
// C++
struct LocalConstantsUI {
float scale = 32.000000f;
float modulo = 2.000000f;
void reflectMembers() {
ImGui::InputScalar( "Scale", ImGuiDataType_Float, &scale);
ImGui::InputScalar( "Modulo", ImGuiDataType_Float, &modulo);
}
void reflectUI() {
ImGui::Begin( "LocalConstants" );
reflectMembers();
ImGui::End();
}
}; // struct LocalConstantsUI
And the GPU constants:
// C++
struct LocalConstants {
float scale = 32.000000f;
float modulo = 2.000000f;
float pad_tail[2];
}; // struct LocalConstants
We could enhance HFX with some syntax to mark the derivate properties and just add the system ones in an explicit buffer layout, and add a layout section in the HFX:
// HFX
properties {
// Using Unity ShaderLab syntax:
scale("Scale", Range(0.0, 100.0)) = 100.0
modulo("Modulo", Float) = 2.0
}
layout {
CBuffer LocalConstants {
float4x4 world_view_projection; // 'System' variable
float scale01 = (scale); // Silly normalized version of scale interface property
float modulo;
float pad[2];
}
}
we could completely override the automatic constant buffer generation from the properties. With this we can:
- Add a system variable like world_view_projection
- Flag the property scale as UI only, by saying that property scale01 uses it.
I think that with this syntax both artists and programmers can be happy together! I will try to work on this on a later article.
Resource bindings: Vulkan and D3D12 mentality
As stated multiple times, the shift in mentality is towards the new APIs, and that includes the concept of resource lists. The problem is that we don’t want artists to have to handle this kind of things - especially if you want to quickly prototype things! But at the same time, we want programmers to have the possibility to optimize the shaders the artists gave them. What is the solution? Simple: creating an optional resource layout section and automatically generate it if not present, so that artists (and not only) can happily create amazing tech and THEN worry about these details!
Automatic Resource Layout
The easiest way to handle resource layout is to make them SIMPLE. Remember the K.I.S.S. principle. In this case it means that we can create a Resource List for each pass, that will contain:
- One constant/uniform buffer containing all the properties
- All the textures used by the shader
How can we achieve that ?
We already saw how we can generate the constant buffer from the properties in the previous section. For textures we have a couple of options.
List of Textures
Being in automation land, there are 2 ways to add texture dependencies:
- Use reflection mechanism from the target shader language
- Parse identifiers in the current finalized shader
For the sake of fun we will look into the second of course!
If we go back to void declarationGlsl( Parser* parser ), we can add a new method to parse the keyword:
// Parse hash for includes and defines
if ( token.type == Token::Token_Hash ) {
// Get next token and check which directive is
nextToken( parser->lexer, token );
directiveIdentifier( parser, token, code_fragment );
}
else if ( token.type == Token::Token_Identifier ) { <------------ New Code!
// Parse uniforms to add resource dependencies if not explicit in the HFX file.
if ( expectKeyword( token.text, 7, "uniform" ) ) {
nextToken( parser->lexer, token );
uniformIdentifier( parser, token, code_fragment );
}
}
In this way it will search for the identifier uniform and search for the other identifiers. This is GLSL centric of course.
inline void uniformIdentifier( Parser* parser, const Token& token, CodeFragment& code_fragment ) {
for ( uint32_t i = 0; i < token.text.length; ++i ) {
char c = *(token.text.text + i);
switch ( c ) {
case 'i':
{
if ( expectKeyword( token.text, 7, "image2D" ) ) {
// Advance to next token to get the name
Token name_token;
nextToken( parser->lexer, name_token );
CodeFragment::Resource resource = { hydra::graphics::ResourceType::TextureRW, name_token.text };
code_fragment.resources.emplace_back( resource );
}
break;
}
case 's':
{
if ( expectKeyword( token.text, 9, "sampler2D" ) ) {
// Advance to next token to get the name
Token name_token;
nextToken( parser->lexer, name_token );
CodeFragment::Resource resource = { hydra::graphics::ResourceType::Texture, name_token.text };
code_fragment.resources.emplace_back( resource );
}
break;
}
}
}
}
Should be pretty straight-forward: if you find the identifier for texture, add a resource dependency with type and name to the current code fragment! Is this the ideal solution ? Probably not. But I wanted to show what we can achieve once we have fun with parsing, including the understanding on when to say NO to it!
Manual Resource Layout
Now that the effect can work without too much programmer time, it is time to give back to programmers the control they want. In the previous paragraph about Expert Constants we talked about adding a new section, called layout. In this section we can specify the resource list for each pass manually, and later on in the pass we can reference this lists as used by the pass.
Going on a more complete solution, layouts should be included and merged when including other HFX files. This is something we want and we’ll look in another post, we can start simple by defining something local:
// HFX
//
// For the developer
layout {
list LocalCompute {
cbuffer LocalConstants;
texture2Drw(rgba8) destination_texture;
}
list Local {
texture2D input_texture;
}
}
This is a rather simple layout, but let’s see it. First of all, for each ‘list’ keyword we define a single list with a unique name. With that, we can reference in the pass which list to use.
The code that does the parsing is (at this point) pretty straight-forward, both in void declarationResourceList( Parser* parser, ResourceList& resource_list ) and void resourceBindingIdentifier( Parser* parser, const Token& token, ResourceBinding& binding ).
I will not go over it, but basically it will parse the resource lists and add them to the shader.
The parsing itself will read the text and create the ResourceSetLayoutCreation::Binding and add it to the list of the resources.
We then add a new identifier in the pass to choose which resource list to be used:
// HFX
//
pass FillTexture {
resources = LocalCompute, ...
dispatch = 32, 32, 1
render_pass = compute
compute = ComputeTest
}
pass ToScreen {
resources = Local
render_pass = fullscreen
vertex = ToScreen
fragment = ToScreen
}
The parsing will happen in void declarationPassResources( Parser* parser, Pass& pass ).
Adding Resource Layout data to binary HFX
So after this amazing journey we are ready to embed those informations into the BHFX and use it right away into the rendering API.
The big difference is if the hfx file contains a layout section.
If it is not present, then all the informations will be gathered automatically and will be added with the writeAutomaticResourcesLayout method.
First we will add the LocalConstant buffer created from the properties:
static void writeAutomaticResourcesLayout( const hfx::Pass& pass, StringBuffer& pass_buffer, uint32_t& pass_offset ) {
using namespace hydra::graphics;
// Add the local constant buffer obtained from all the properties in the layout.
hydra::graphics::ResourceSetLayoutCreation::Binding binding = { hydra::graphics::ResourceType::Constants, 0, 1, "LocalConstants" };
pass_buffer.append( (void*)&binding, sizeof( hydra::graphics::ResourceSetLayoutCreation::Binding) );
pass_offset += sizeof( hydra::graphics::ResourceSetLayoutCreation::Binding );
Then we will cycle through all the shader stages and write the resources into the memory:
for ( size_t s = 0; s < pass.shader_stages.size(); ++s ) {
const Pass::ShaderStage shader_stage = pass.shader_stages[s];
for ( size_t p = 0; p < shader_stage.code->resources.size(); p++ ) {
const hfx::CodeFragment::Resource& resource = shader_stage.code->resources[p];
switch ( resource.type ) {
case ResourceType::Texture:
{
copy( resource.name, binding.name, 32 );
binding.type = hydra::graphics::ResourceType::Texture;
pass_buffer.append( (void*)&binding, sizeof( hydra::graphics::ResourceSetLayoutCreation::Binding ) );
pass_offset += sizeof( hydra::graphics::ResourceSetLayoutCreation::Binding );
break;
}
case ResourceType::TextureRW:
{
copy( resource.name, binding.name, 32 );
binding.type = hydra::graphics::ResourceType::TextureRW;
pass_buffer.append( (void*)&binding, sizeof( hydra::graphics::ResourceSetLayoutCreation::Binding ) );
pass_offset += sizeof( hydra::graphics::ResourceSetLayoutCreation::Binding );
break;
}
}
}
}
}
If instead there is a layout section, the method writeResourcesLayout is called and will be pretty straight-forward:
static void writeResourcesLayout( const hfx::Pass& pass, StringBuffer& pass_buffer, uint32_t& pass_offset ) {
using namespace hydra::graphics;
for ( size_t r = 0; r < pass.resource_lists.size(); ++r ) {
const ResourceList* resource_list = pass.resource_lists[r];
const uint32_t resources_count = (uint32_t)resource_list->resources.size();
pass_buffer.append( (void*)resource_list->resources.data(), sizeof(ResourceBinding) * resources_count );
pass_offset += sizeof( ResourceBinding ) * resources_count;
}
}
And this will be put at the end of the current pass section:
pass_buffer.append( (void*)&pass_header, sizeof( ShaderEffectFile::PassHeader ) );
pass_buffer.append( shader_offset_buffer );
pass_buffer.append( code_buffer );
if ( automatic_layout ) {
writeAutomaticResourcesLayout( pass, pass_buffer, pass_offset );
}
else {
writeResourcesLayout( pass, pass_buffer, pass_offset );
}
Conclusions and what’s next
We arrived at the end of this article, and we started seeing how we can use HFX as a more complete language to embed different rendering features. We saw how to embed shader code and resource lists so that the rendering API can create everything without hard-coded generation of resources. This also showed when it was useful to create data instead of code. On the contrary, the UI and the Constants are generated in a new header file - thus code generation. There are pros and cons to both approaches, but I hope that knowing how to generate code and create a custom language will let you play with the concepts and explore your own needs.
As next steps, there are some questions opened: how to reload shaders ? Can I add new material properties without recompiling code ?
We will also see a simple implementation of a frame-graph, that I use since my years in Codemasters and in my indie project. This will be much more data-driven than code-generated, but again, the purpose of these articles is to explore the concepts and understanding when to use what.
As always please comment, feedback, share!
Thanks for reading! Gabriel